Quel avenir pour PostgreSQL ?
- 12 minutes de lecture
À moins d’avoir passé la dernière décennie dans une grotte ou un service informatique vieillissant, chacun·e des acteur·rice·s de l’IT a dû entendre parler du projet PostgreSQL, ne serait-ce que son nom inintelligible. La page d’accueil est par ailleurs catégorique : il s’agit du moteur relationnel open-source le plus avancé au monde. (PostgreSQL: The World’s Most Advanced Open Source Relational Database)
Comment expliquer ce succès ? D’ailleurs, quelles sont les tendances du produit et comment s’articule la vie d’un logiciel aussi ambitieux ? Est-il possible de voir émerger en France un mouvement massif de migration vers ce moteur, alors même qu’Oracle et Microsoft ont une part de marché importante sur les grands secteurs de la santé, du bancaire ou de la grande distribution ?
Historique du projet et cycle de vie
Ce projet est ancien, très ancien. Même qu’il est plus vieux que le Web lui-même. Il a été initié en 1986 par un professeur et son équipe à l’université de Californie à Berkeley avec le soutien de plusieurs sponsors. À l’origine de ce projet, la volonté d’améliorer un autre projet de l’université de Californie, exprimée dans l’extrait du document ci-dessous.
The INGRES relational database management system (DBMS) was implemented during 1975-1977 at the University of California. Since 1978 various prototype extensions have been made to support distributed databases, ordered relations, abstract datatypes, and QUEL as a data type. In addition, we proposed but never prototyped a new application program interface. The University of California version of INGRES has been ‘‘hacked up enough’’ to make the inclusion of substantial new function extremely difficult. Another problem with continuing to extend the existing system is that many of our proposed ideas would be difficult to integrate into that system because of earlier design decisions. Consequently, we are building a new database system, called POSTGRES (POSTinGRES).
Pour l’anecdote, le projet mentionné (INGRES) a par la suite permis l’émergence de produits sous licence commerciale comme Microsoft SQL Server ou Sybase (propriété actuelle de l’éditeur SAP).
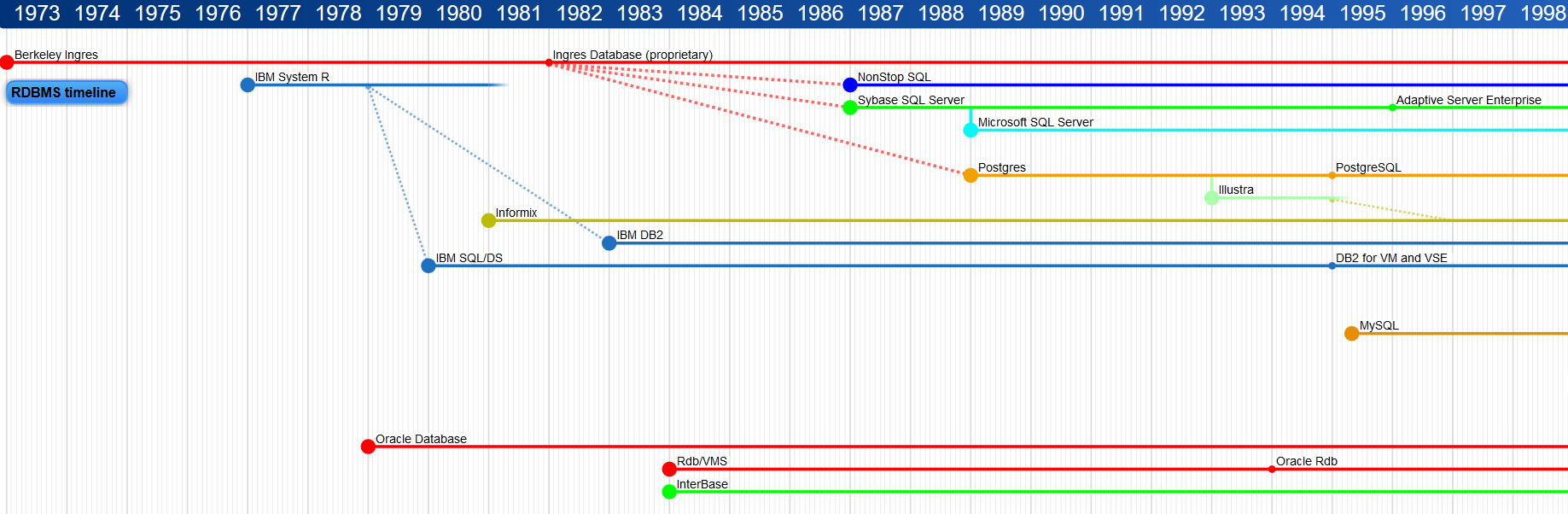
Les années 1990 à 1994 virent des versions successives fiabiliser le produit jusqu’à une nouvelle branche open-source appellée Postgres95, puis PostgreSQL, intégrant l’interpréteur du language SQL connu aujourd’hui. Aussi, tout appellation « Postgres » au-delà de cette date est un simple abus de langage.
Le cycle de développement qui suivit fut régulier, à raison d’une nouvelle release chaque année avec un apport en fonctionnalités et en performance. Entre 1997 et 2018, ce n’est pas moins de 25 versions majeures et 112 fonctionnalités qui furent mises à disposition du grand public en téléchargement gratuit et libre.
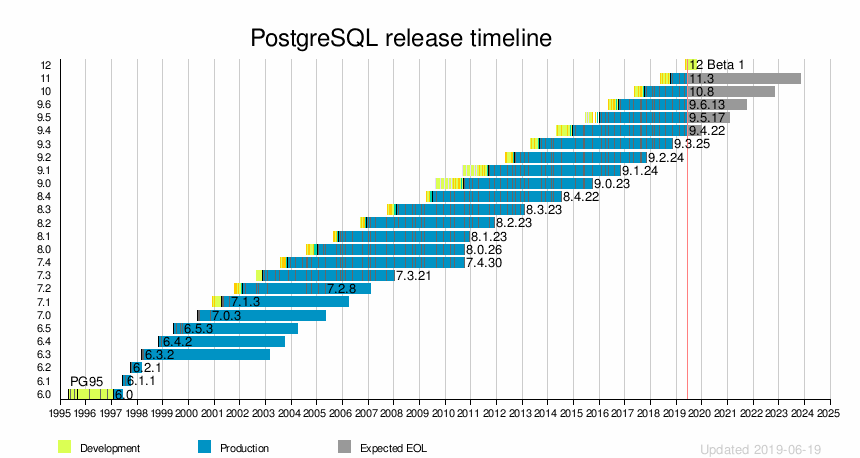
Source : https://docs.postgresql.fr/12/history.html
Gouvernance et contributions
Lorsqu’on s’intéresse au milieu de l’open-source, il est très courant de voir des projets vivre et mourrir comme des étoiles dans un univers chaotique. La beauté de cette chorégraphie peut s’expliquer par le foisonnement d’idées et de contributions libres dans un monde connecté où les barrières linguistique et culturelle n’existent plus. Un produit peut apparaître à un moment décisif dans un écosystème et peut être accueilli par un ensemble d’acteurs hétérogènes, ou bien, peut disparaître à défaut de maintenance/consensus ou au profit d’une alternative. C’est la jungle, ou plus précisemment : le bazar.
En ce qui concerne le projet PostgreSQL, ce qui explique sa longévité et son assise actuelle est sans conteste l’approche verticale de la gouvernance. Une page officielle recense les membres actifs du projet à travers trois distinctions : la Core Team (une sorte de comité de pilotage), les Major Contributors et les Contributors. Le processus de mise à disposition d’une contribution est tout à fait intéressant et diffère des pull-requests habituelles des autres projets open-source.
Exemple pour un patch (source) :
Le développeur lambda fait une demande mail sur la liste de diffusion
pgsql-hackers@postgresql.org et plusieurs scénarii sont possibles :
- Un contributeur intégre immédiatement la correction dans la prochaine release
- Le patch est ajouté dans la liste du prochain CommitFest et sera confronté à l’avis d’un comité de contributeurs pendant 3 à 4 mois avant d’être intégré dans le produit
- Le patch est rejeté pour des raisons diverses avec un commentaire pour l’améliorer avant de le relivrer
Devenir contributeur prend du temps et nécessite un investissement dans un composant du projet, comme l’ajout ou l’amélioration d’une fonctionnalité ou la correction des bogues du moteur. C’est ce qu’a témoigné Dimitri Fontaine lors d’un interview pour LinuxFR.
Ma contribution suivante a porté sur les Event triggers. Sur la liste de diffusion, Jan Wieck avait indiqué que ça devait être assez facile à mettre au point : à la lecture de son message, je me suis dit qu’il devait avoir raison et j’ai commencé le développement. Ça m’a pris 18 mois.
Le français Michael Paquier également a réalisé cet exploit en participant depuis 2009 au PostgreSQL Global Development Group avec le suivi de la mailing-list et la publication très régulière d’articles sur son blog pour expliquer chacune de ses contributions. Une véritable mine d’informations !
Contribuer à un projet open-source ne se réduit pas au développement de fonctionnalités ou de correctifs. PostgreSQL n’échappe pas à cette règle, et l’on a vu fleurir des groupes de passionné·e·s faire la promotion du produit à travers le monde entier. Leurs formes sont évidemment multiples : traduction de la documentation anglaise (la version française est largement traduite par Guillaume Lelarge) ou encore l’animation d’évenements tel que la PG Day ou la PG Conf majoritairement sponsorisées par des entreprises.
Je ne parle volontairement pas des outils tiers qui soutiennent la dynamique du projet PostgreSQL, avec des contributions d’individus ou d’entités plus organisées. Nous verrons juste après l’intérêt que portent de nombreux acteurs pour cette exception logicielle.
La maturité
Il est tout à fait impossible de cartographier l’usage d’un produit open-source en milieu d’entreprise. Une initiative française s’illustre en réunissant de nombreux acteurs dans un groupe dédié à la promotion et la standardisation des outils. Les cabinets de conseils et sociétés de service autours de PostgreSQL sont encore dans un marché de niche ; mon intuition me pousse à croire qu’une tendance se dessine tout de même sur le territoire français.
Sur les seules cinq années écoulées, j’ai pu apprécier une forte émulation autours du produit PostgreSQL. Parmi les DBA (Oracle accessoirement) que je fréquentais ou suivais sur les réseaux, j’ai vu une poignée d’entre eux afficher la double compétence Oracle/PostgreSQL sur leur fiche descriptive. Les blogs d’entreprises spécialisées diffusaient des contenus inédits et de très bonne qualité là où nous ne les attendions pas (exemples comme Percona, dbi-services, Digora ou encore Easyteam).
Côté service public, la Direction interministérielle des systèmes d’information et de communication publie depuis 2014 la liste des logiciels de bases de données open-source à privilégier avec PostgreSQL au côté de MariaDB et SQLite. En début d’année 2019, elle maintient sa position en encourageant l’usage de la version 10 de PostgreSQL. A titre d’exemple, durant la PG Day 2016, j’avais été surpris par l’appropriation du produit au sein de la Gendarmerie Nationale avec un retour d’expérience agréable.
Ma lecture pour cet engouement serait à la fois technique et engagée.
J’ai observé de nette avancée dans les fonctionnalités durant les trois précédentes années, avec notamment des solutions de performances qui n’ont plus à rougir face aux produits leaders du marché (Oracle et SQL Server). Je pense essentiellement au support de la parallélisation des ressources CPU apporté dans la version 9.6 et sans cesse amélioré à chaque nouvelle release, alors que cette même capacité est absente en version Standard (SE2) d’Oracle Database et limitée en version Standard SQL Server.
La version 10 a changé la donne pour les bases de données à haute volumétrie avec la réécriture du module de partitionnement qui reposait sur de l’héritage de tables et un mix de triggers et de contraintes. À présent, la création et la maintenance des tables partitionnées sont simplifiées avec une nouvelle syntaxe déclarative, bien qu’encore limitées en attendant les prochaines versions. Chez la concurrence, les choses sont plus avancées. Oracle proprose un partitionnement poussée sous licence Entreprise + option avec notamment la gestion forte des contraintes ou du sous-partitionnement ; SQL Server impose son implémentation à l’aide de fonctions et de schémas de partition mais autorise son utilisation pour la version Standard depuis la version 2016 SP1.
Avec du retard, la version 11 de PostgreSQL implémente les procédures stockées et le support transactionnel. Cela n’a l’air de rien, mais c’est essentiel pour un grand nombre de projets dont la logique métier est déportée au plus proche du moteur, pratique courrante sur les bases Oracle avec le langage PL/SQL. Cette avancée ouvre les portes à de possibles migrations Oracle vers PostgreSQL en réécrivant l’ensemble des procédures stockées dans le bon format !
De bonnes choses sont encore à prévoir avec la prochaine release 12, où l’option
CONCURRENTLY est à présent supportée lors de la réindexation. Cette
fonctionnalité stabilise grandement le produit pour les bases à forte activité et
forte volumétrie, où les opérations de maintenance ne doivent en aucun cas
perturber les requêtes courantes. Sans vouloir me répéter, Oracle et SQL Server
proposent ce mécanisme en version Entreprise exclusivement…
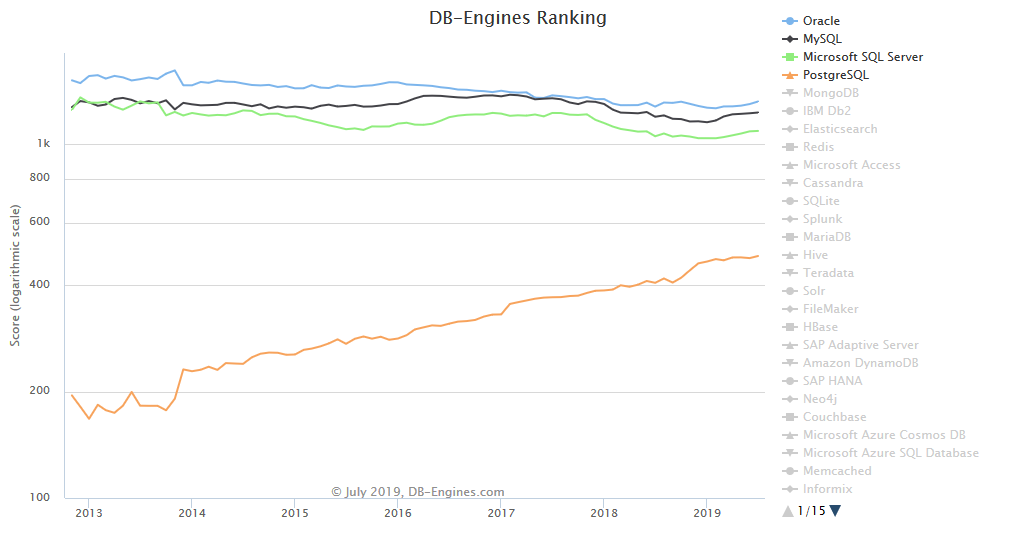
Mises bout à bout, ces fonctionnalités redessinent le paysage numérique et poussent de nombreuses sociétés à revoir leur copie en terme de licence ou de politique d’architecture. La popularité pour ce produit n’a pas terminée son ascension, à en croire le classement annuel des moteurs de bases de données.
Les travers des contributions tierces
Il existe bien d’autres fonctionnalités que j’affectionne dans PostgreSQL, qu’il faut absolument connaître pour faire un choix crucial en début de projet, je pourrais parler plus longuement du hot backup et du hot standby, deux modes de fonctionnements pour la sauvegarde et la lecture seule sur une base répliquée (Oracle Active Dataguard est une option payante.) ou alors des très récents index couvrants apparus en version 11, faisant de l’ombre à SQL Server. Mais tout n’est pas glorieux, et les contributeurs du projet PostgreSQL ont encore un grand défi à surmonter : la Haute Disponibilité.
Je disais donc, la Haute Disponibilité est une des fonctionnalités les plus demandées lorsque l’on traite d’une architecture où le cœur d’un système repose sur un moteur de bases de données. Elle consiste à apporter une solution technique de gestion de ressources en cas de panne dans le système. Un incendie ? Une panne de disque ? Une erreur humaine sur le serveur ? PostgreSQL propose une réplication aux petits oignons pour assurer la copie des données en temps réel sur un second serveur ou datacenter.
Cependant, la détection de l’anomalie, la bascule des flux de connexions et l’activation de la base secondaire ne sont pas nativement implémentées. Et alors que les produits concurrents y répondent à grands coups de Real Application Cluster (Oracle Database) ou de Always On (SQL Server), le produit communautaire se voit contraint de bénéficier d’outils tiers, souvent de haut niveau, qui rendent très vite complexe l’architecture globale.
La documentation actuelle fait l’état des lieux de solutions vieillissantes et/ou abandonnées (exemple de Londiste, non maintenue depuis 2014). D’autres comme pgpool-II ou repmgr, présents dans le paysage depuis très longtemps, rencontrent une concurrence avec des alternatives plus modernes comme Patroni développé par Zalando ou plus récemment le package pg_auto_failover offert à la communauté par Microsoft. D’autres encore, détournent les mécanismes de réplication pour répondre à d’autres besoins comme l’architecture multi-master où chaque nœud peut répondre à des requêtes d’écriture. À ce jeu là, il est possible de tomber sur des solutions comme Postgres-DBR sous licence 2ndQuadrant ou Bucardo en accès libre.
Que penser de ces contributions ? Faut-il payer pour une fonctionnalité qui n’existe pas… ou pas encore ? Ou miser sur un produit tendance et moderne à la place d’un autre qui pourrait ne plus être maintenu ? Le choix n’est pas aisé, et la réponse que le DBA doit apporter, lourde de conséquences sur les systèmes de production.
Faut-il miser sur l’alternative que devient PostgreSQL ?
Compte tenu que PostgreSQL est un logiciel open-source et que ce dernier respecte les libertés de la Free Software Foundation (bien qu’il n’utilise pas de license GNU GPL), tout le monde peut l’exécuter librement et dans l’environnement qu’il souhaite, ainsi que le modifier et le distribuer aux tarifs qu’il entend !
Dans ce contexte, les offres cloud se sont multipliées auprès des fournisseurs que l’on connait tous. Amazon avec Aurora et Redshift, Microsoft avec Hyperscale et Google avec ses déclinaisons Cloud SQL. Toutes ces propositions, pour ne citer que les providers les plus puissants, constituent un tremplin phénomal pour l’adoption de PostgreSQL à l’heure du Go to Cloud engagé par les DSI de grands groupes français.
Encourager l’alternative, c’est lutter contre les positions dominantes et entrer dans un dialogue technologique pour développer et améliorer nos outils du quotidien. Nous ne sommes pas à l’abri des contre-ripostes des géants du Web comme mentionnés plus haut et cette bataille pour la liberté ébranle depuis le début de notre siècle notre rapport à l’outil informatique.
En s’intéressant à la gouvernance et à la maturité de PostgreSQL, on pourrait entrevoir un essort confortable et rassurant d’un logiciel open-source, dont la popularité n’est plus à discuter. L’adoption et l’usage d’un tel outil présuppose que l’utilisateur soit conscient des efforts de longues dates qui ont permit son ascension.
Choisir PostgreSQL, c’est s’engager dans un combat où s’affronte deux idéologies : celle du logiciel libre et celle de la propriété intellectuelle ; s’opposer aux industries du logiciel pour garantir l’émergence du partage et de l’éthique au cœur de la technologie toujours plus grandissante.
« Internet ou la révolution du partage » est un excellent reportage Arte où le réalisateur Philippe Borrel traite de la question de la liberté dans le logiciel. Il n’appartient qu’à nous d’entrer dans ce mouvement !