Le jour où tout bascule
- 10 minutes de lecture
Lorsque l’on exploite une plateforme PostgreSQL avec de la réplication, il est exceptionnel de devoir déclencher le plan de bascule, rédigé par un ancien collègue ou un prestataire oublié. Ce genre de décision se prend lorsque l’ensemble des experts ont individuellement déterminé qu’aucune autre solution n’était envisageable.
Quels moyens a-t-on avec une architecture PostgreSQL dans son plus simple appareil pour réaliser une bascule des rôles et raccrocher les instances secondaires au nouveau primaire fraîchement élu ?
Mise en place
Partons du postulat que l’architecture la plus simple en terme de haute-disponibilité avec PostgreSQL est constituée de deux services avec une réplication physique d’une instance primaire vers une instance secondaire.
Pour des raisons de coûts, aucun serveur supplémentaire n’est alloué pour accueillir
les archives de journaux de transactions, et ces derniers seront déplacés sur le
serveur secondaire avec la commande rsync.
Et puisque la version 12 apporte des nouveautés notables sur la gestion d’une
réplication, nous l’employerons dans cet article pour configurer nos instances
sans le fichier recovery.conf. Pour la facilité de lecture, je baptiserai
volontairement les deux serveurs : batman et robin.
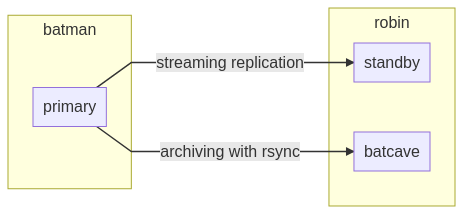
L’instance batman dispose de la configuration suivante :
# postgresql.auto.conf
port = 5432
archive_mode = on
wal_log_hints = on
archive_command = 'rsync -a %p robin:/opt/batcave/%f'
restore_command = 'cp /opt/batcave/%f %p'
archive_cleanup_command = 'pg_archivecleanup /opt/batcave %r'
primary_conninfo = 'host=batman user=streamer'
Le fichier postgresql.auto.conf permet de surcharger les valeurs présentes dans
le fichier standard postgresql.conf et, avantage certain sur une distribution
Debian & co, il est accessible dans le répertoire de données PGDATA et pourra
être copié en l’état vers toutes les instances secondaires au moment de leur
création.
Cette étape par ailleurs repose sur un outil simple et fourni avec toutes les
versions PostgreSQL : pg_basebackup. L’unique prérequis est de disposer d’un
compte de réplication sur l’instance à répliquer et que le serveur distant puisse
réaliser une authentification valide (fichier pg_hba.conf).
cd /opt
pg_basebackup --host=batman --user=streamer \
--pgdata=robin --wal-method=stream --checkpoint=fast
touch robin/standby.signal
pg_ctl start -D robin
Un autre outil existe pour contrôler l’état d’une instance en scannant le contenu
du fichier PGDATA/global/pg_control, notamment pour savoir si notre serveur est
primaire ou secondaire et s’il réplique les journaux de transactions :
pg_controldata -D robin
# pg_control version number: 1201
# Catalog version number: 201909212
# Database system identifier: 6771436906102136159
# Database cluster state: in archive recovery
# Latest checkpoint location: 0/A000098
# Latest checkpoint's REDO location: 0/A000060
# Latest checkpoint's REDO WAL file: 00000001000000000000000A
# wal_level setting: replica
# wal_log_hints setting: on
# WAL block size: 8192
# Data page checksum version: 0
La bascule
À présent, mettons de la forme à notre incident.
Vous revenez de pause déjeûner aux alentours de 13:30 et le service support est alerté depuis midi de la perte d’un composant réseau sur votre datacenter principal. Toute la charge a basculé et les services web sont redirigées correctement… Pas de bol, les frontaux remontent des erreurs et la navigation est en mode dégradé : l’instance secondaire est en lecture seule, et l’on vous attendait pour corriger le tir !
Ni une ni deux, un accès au serveur robin et une commande solutionnent le
problème :
pg_ctl promote -D robin
# FATAL: terminating walreceiver process due to administrator command
# LOG: invalid record length at 0/A000148: wanted 24, got 0
# LOG: redo done at 0/A000110
# LOG: selected new timeline ID: 2
# LOG: archive recovery complete
# LOG: database system is ready to accept connections
L’instance robin est donc promue, elle acceptera toutes les demandes d’écriture
en contrepartie d’une nouvelle ligne de temps (timeline) dédiée aux futures
transactions.
Je passe la scène des grandes accolades et chaleureux compliments qui n’auront
jamais lieu car les équipes ont déjà d’autres chats à fouetter ; après tout,
soyez réaliste, vous n’avez exécuté qu’une seule commande ! Autant dire, vous
prenez votre pause, et alors que coule votre café, vous apprenez par
l’intermédiaire du delivery manager que le client rencontre des dégradations
de performance sur son backoffice depuis la perte du nœud batman. Mais, de
quoi parle-t-il ?
Et l’architecture globale vous revient en mémoire. Une goûte perle votre front :
l’instance secondaire est utilisée pour répartir la charge de lecture entre chaque
nœud à l’aide de l’attribut de préférence target_session_attrs (documentation)
et aucun mécanisme d’éviction en cas de split-brain ou de VIP flottante n’ont
été déployés sur vos serveurs…
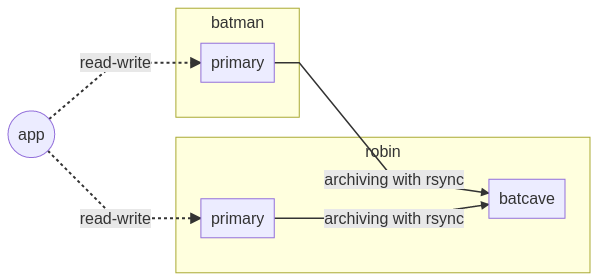
Synchronisation
L’urgence impose d’intervenir sur les chaînes de connexion pour réduire le risque
de modification sur la mauvaise timeline. Vous recommandez à l’équipe support
de retirer l’IP batman de tout ce qui s’apparente à un fichier settings_db.xml :
postgresql://app@batman,robin/gotham?target_session_attrs=read-write
# devient
postgresql://app@robin/gotham?target_session_attrs=read-write
Les performances ne sont bien évidemment pas meilleures, mais tout risque de perte de données lié au split-brain est écarté. Le timing est parfait, car au même moment, l’équipe système vous informe que l’intervention au datacenter a permis la remise en réseau des serveurs, toujours actifs.
Votre rôle consiste donc à rétablir la synchronisation entre batman et robin
pour accomplir leur mission de répartition de charge. La première méthode disponible
réside dans le duo gagnant pg_start/stop_backup() et rsync pour réaliser à
la main une sauvegarde physique différentielle.
Première méthode
Puisque la sauvegarde exclusive est annoncée obsolète depuis la version 9.6,
nous déclarerons le début d’une sauvegarde concurrente sur l’instance primaire
robin à l’aide de la commande suivante et nous maintiendrons la connexion :
SELECT pg_start_backup('rsync the batman', true, false);
-- pg_start_backup
-- -----------------
-- 0/15000028
Sur le nœud batman, on peut alors transférer les données avec l’option
--whole-file de la commande rsync pour réduire le risque de corruption des
fichiers de données :
cd /opt
pg_ctl stop -D batman
rsync robin:/opt/robin/ batman --archive --checksum --whole-file
À l’issue de cette copie victorieuse, n’oubliez pas de lancer la commande
pg_stop_backup() sur l’instance primaire pour finaliser la sauvegarde et la
rendre valide.
SELECT labelfile FROM pg_stop_backup(false) \gx
-- -[ RECORD 1 ]-------------------------------------------------------------
-- labelfile | START WAL LOCATION: 0/15000028 (file 000000020000000000000015)+
-- | CHECKPOINT LOCATION: 0/15000060 +
-- | BACKUP METHOD: streamed +
-- | BACKUP FROM: master +
-- | START TIME: 2019-12-17 16:21:21 CET +
-- | LABEL: rsync the batman +
-- | START TIMELINE: 2 +
La dernière étape devient bordélique, mais n’ayez crainte, ça ne dure pas
longtemps. Les commandes sont à exécuter sur l’instance secondaire batman et
s’assurent notamment que l’instance redémarre avec les bons paramètres de
réplication, dont primary_conninfo et les fichiers standby.signal et
backup_label.
sed -i -e 's/batman/robin/g' batman/postgresql.auto.conf
rsync robin:/opt/robin/pg_wal/ batman/pg_wal \
--archive --checksum --whole-file
# récupération des instructions backup_label présentes dans
# le fichier .backup généré par la commande pg_stop_backup()
grep -iv ^stop batman/pg_wal/000000020000000000000015.00000028.backup \
> batman/backup_label
rm batman/postmaster.pid
touch batman/standby.signal
pg_ctl start -D batman
# LOG: entering standby mode
# LOG: restored log file "00000002.history" from archive
# LOG: restored log file "000000020000000000000015" from archive
# LOG: redo starts at 0/15000028
# LOG: consistent recovery state reached at 0/15000138
# LOG: database system is ready to accept read only connections
# LOG: invalid record length at 0/16000148: wanted 24, got 0
# LOG: started streaming WAL from primary at 0/16000000 on timeline 2
L’état intermédiaire de notre cluster peut être visualisé comme suit. On constate
que la zone d’archivage (batcave) réside donc sur le même serveur que l’instance
nouvellement primaire robin et pourrait être un risque en cas de surincident.
De manière générale, il est recommandé d’externaliser systématiquement les archives
et les sauvegardes !
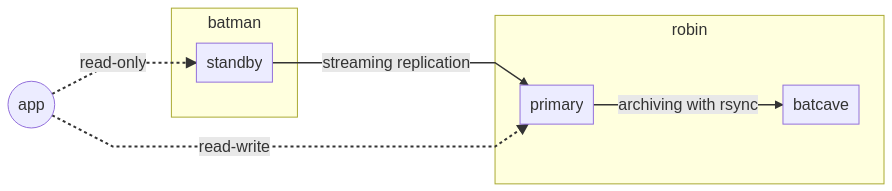
Vous y conviendrez, cette étape était particulièrement coton pour l’envisager
dans une situation passablement stressante. Voyons ensemble l’autre solution plus
adaptée à notre scénario : la commande pg_rewind.
Deuxième méthode
La situation reste inchangée, i.e. l’instance batman est primaire sur une
ancienne timeline et doit être resynchronisée avec robin pour obtenir toutes
les modifications réalisées depuis sa promotion.
Comme suggéré dans la documentation, le compte de réplication streamer
doit disposer des droits d’exécution sur certaines fontions internes pour
utiliser l’outil pg_rewind correctement :
\connect postgres
GRANT EXECUTE ON
function pg_ls_dir(text, boolean, boolean) TO streamer;
GRANT EXECUTE ON
function pg_stat_file(text, boolean) TO streamer;
GRANT EXECUTE ON
function pg_read_binary_file(text) TO streamer;
GRANT EXECUTE ON
function pg_read_binary_file(text, bigint, bigint, boolean) TO streamer;
Sur le serveur batman, l’instance doit être arrêtée avant de lancer la
synchronisation et le contenu de la zone d’archivage batcave doit être copié
manuellement vers le répertoire de récupération pg_wal ; il s’agit de reproduire
l’instruction restore_command que ne peut pas exécuter l’instance lorsqu’elle
est éteinte.
pg_ctl stop -D batman
rsync robin:/opt/batcave/ batman/pg_wal \
--archive --checksum --whole-file
pg_rewind -D batman \
--source-server="host=robin user=streamer dbname=postgres"
# pg_rewind: servers diverged at WAL location 0/8000060 on timeline 1
# pg_rewind: rewinding from last common checkpoint at 0/7000060 on timeline 1
# pg_rewind: Done!
Le résultat de la commande pg_rewind nous informe que batman est revenu à
la position de sa timeline au moment de la promotion de robin. Cette opération
repose sur un format étendu des journaux de transactions, désactivé par défaut.
Les plus attentifs auront constaté le paramètre wal_log_hints=on(documentation)
dans le fichier postgresql.auto.conf en début d’article, qui est l’un des
prérequis de l’outil pg_rewind.
pg_rewind requires that the target server either has the wal_log_hints option enabled in postgresql.conf or data checksums enabled when the cluster was initialized with initdb. Neither of these are currently on by default. full_page_writes must also be set to on, but is enabled by default.
La dernière étape consiste à modifier la chaîne primary_conninfo et ajouter le
fichier standby.signal avant de démarrer l’instance batman :
sed -i -e 's/batman/robin/g' batman/postgresql.auto.conf
touch batman/standby.signal
pg_ctl start -D batman
# LOG: entering standby mode
# LOG: restored log file "00000002.history" from archive
# LOG: restored log file "000000010000000000000007" from archive
# LOG: redo starts at 0/7000028
# LOG: restored log file "000000020000000000000008" from archive
# LOG: started streaming WAL from primary at 0/9000000 on timeline 2
# LOG: consistent recovery state reached at 0/904B5C8
Inversion des rôles
Cette opération permet la remise en place des rôles à leur état nominal. Ainsi,
batman reprendra le contrôle et robin deviendra son second. Les étapes sont
relativement simples :
- Arrêter proprement l’instance
robinpour écrire les caches sur disque, notamment les dernières transactions dans les journaux mais également, pour envoyer toutes les modifications à travers le flux de réplication versbatman;
pg_ctl stop -D robin
- Contrôler optionnellement que les positions sont identiques entre les deux instances ;
pg_controldata -D robin | grep -iE "(cluster state|checkpoint location)"
# Database cluster state: shut down
# Latest checkpoint location: 0/A000028
pg_controldata -D batman | grep -iE "(cluster state|checkpoint location)"
# Database cluster state: in archive recovery
# Latest checkpoint location: 0/A000028
- Promouvoir la nouvelle instance primaire
batman;
pg_ctl promote -D batman
# LOG: received promote request
# LOG: redo done at 0/A000028
# LOG: selected new timeline ID: 3
# LOG: archive recovery complete
# LOG: restored log file "00000002.history" from archive
# LOG: database system is ready to accept connections
- Configurer
robinen instance secondaire et la démarrer.
touch robin/standby.signal
pg_ctl start -D robin
# LOG: restored log file "00000003.history" from archive
# LOG: entering standby mode
# LOG: restored log file "00000003.history" from archive
# LOG: restored log file "00000003000000000000000A" from archive
# LOG: restored log file "00000002.history" from archive
# LOG: consistent recovery state reached at 0/A0000A0
# LOG: redo starts at 0/A0000A0
# LOG: database system is ready to accept read only connections
# LOG: started streaming WAL from primary at 0/B000000 on timeline 3
Depuis la version 12, le paramètre recovery_target_timeline est défini sur la
valeur latest par défaut, ce qui permet à l’instance secondaire de détecter le
saut de timeline provoqué par une promotion et de raccrocher correctement les
transactions à répliquer avant de se connecter en streaming à l’instance primaire.
Conclusion
L’architecture proposée répond à plusieurs problématiques assez fréquentes mais présente un certain nombre d’inconvénients. À travers cet article, nous avons parcouru l’ensemble des outils disponibles nativement avec PostgreSQL.
Comme rappelé précédemment, il est fortement conseillé de décentraliser la zone d’archivage sur un système de fichiers redondé pour se prévenir de l’absence d’un nœud. Le diagramme suivant présenterait alors le moins de risque possible tout en assurant un niveau de service acceptable, avec un minimum d’actions en cas de bascule :
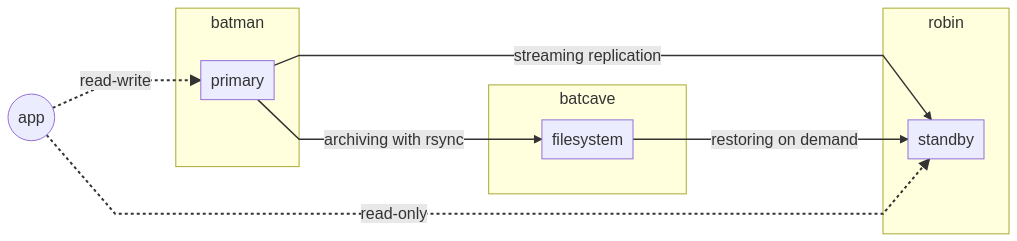
La détection de panne et la bascule automatique sont des thématiques récurrentes
lorsque l’on exprime un besoin de haute-disponibilité. Durant l’année 2019, une
série d’outils tiers ont assis leur réputation avec notamment patroni de
Zalando qui propose intelligemment l’usage de pg_rewind dans son fonctionnement.