Les liens physiques avec pg_upgrade
- 8 minutes de lecture
La création d’un lien sous Unix se réalise avec les commandes ln ou cp. Cette action permet de lier deux fichiers vers la même donnée et de rendre disponible une ressource par l’intermédiaire de l’un ou de l’autre de ces fichiers.
Cependant, les opérations diffèrent selon le type de ce lien. Le plus connu reste le symlink, le lien symbolique. Mais qu’en est-il des autres ? Comment se caractérisent-ils et dans quels contextes ? En vrai, qu’est-ce qu’un inode ? Et PostgreSQL dans tout ça ? Autant de petites questions de curiosité que j’aborde avec vous dans cet article !
Parlons d’abord du lien symbolique
Pour faire simple, on peut comparer le lien symbolique à un raccourci Windows. Il s’agit d’un pointeur vers un fichier ou un répertoire qui permet toutes les opérations simples comme la lecture ou l’écriture.
Par exemple, pour une instance PostgreSQL, il est possible de déporter le répertoire des fichiers WAL sur un autre montage à l’aide d’un lien symbolique. Cette opération nécessite un arrêt du service et la copie des fichiers vers le nouveau montage, comme suit :
# à réaliser avec le compte root
systemctl stop postgresql-12.service
# créer le nouveau répertoire en préservant les permissions
install --owner=postgres --group=postgres --mode=700 -d /u01/pg_wal/12
mv /var/lib/pgsql/12/data/pg_wal/* /u01/pg_wal/12/
# créer le lien vers le nouveau répertoire
rmdir /var/lib/pgsql/12/data/pg_wal
ln --symbolic /u01/pg_wal/12 /var/lib/pgsql/12/data/pg_wal
# et redémarrer l'instance
systemctl start postgresql-12.service
Le lien ainsi obtenu par la commande ln --symbolic se présente comme une fausse
copie du répertoire d’origine, permettant aux données d’être consultées à plusieurs
endroits sans risque d’être dupliquées. La commande stat nous donne de précieuses
informations à son sujet :
# FORMAT="File = %N\nType = %F\nOwner = %U:%G\nAccess = %A\nInode = %i\n"
# stat --printf="$FORMAT" /var/lib/pgsql/12/data/pg_wal
File = ‘/var/lib/pgsql/12/data/pg_wal’ -> ‘/u01/pg_wal/12’
Type = symbolic link
Owner = root:root
Access = lrwxrwxrwx
Inode = 33725146
Il apparait que son propriétaire est root, que son accès est ouvert à tous, et
que l’inode qui lui est associé vaut 33919915. Qu’en est-il de répertoire
contenant les journaux de transactions ?
# stat --printf="$FORMAT" /u01/pg_wal/12
File = ‘/u01/pg_wal/12’
Type = directory
Owner = postgres:postgres
Access = drwx------
Inode = 33867963
Les deux fichiers sont bien distincts et présentent des différences notables, comme les propriétaires et les droits d’accès. En réalité, Unix propose sept types de fichiers et chacun présente des caractéristiques et comportements que lui sont propres. On retrouve ainsi les fichiers, répertoires, liens symboliques, mais aussi les named pipes, les sockets, les devices ou les doors.
Le dernier attribut que remonte ma commande stat correspond au inumber ou
numéro inode. Il s’agit d’un identifiant unique sur le système de fichiers
permettant de retrouver toutes les métadonnées du fichier dans une table d’inodes.
Nous avions vu à l’instant les droits et le propriétaire, l’inode permet
également de stocker les horodatages de création ou de modification ainsi que
l’adresse physique des données du fichier sur le disque.
Ainsi, pour chaque fichier sur notre système lui est associé un inode. La représentation suivante permet donc de comprendre la relation entre un lien symbolique et un répertoire.

Le mode --link de pg_upgrade
Les choses sont devenues passionnantes lorsque j’ai découvert la notion de lien physique, ou hardlink, qu’il était possible de créer entre deux fichiers. Ce n’est en rien une nouveauté, car inclu dans les systèmes Unix depuis longtemps mais ça m’a permis de comprendre davantage l’intérêt des fameux inodes.
Puisqu’un exemple concret parle toujours de lui-même, je propose d’étudier la
méthode de migration de données d’une version 9.6 vers une version 12 de
PostgreSQL avec l’outil pg_upgrade. Ce dernier propose l’option --link pour
réduire le temps de migration des données sans copier les fichiers d’une instance
à l’autre. Bien sûr, ce n’est pas le comportement par défaut.
# la routine setup permet la création du fichier de service ainsi
# que l'initilisation d'un répertoire de données minimaliste
/usr/pgsql-12/bin/postgresql-12-setup initdb postgresql-12
# durant la migration, l'instance 9.6 doit être arrêtée
systemctl stop postgresql-9.6.service
export PGDATAOLD=/var/lib/pgsql/9.6/data
export PGDATANEW=/var/lib/pgsql/12/data
export PGBINOLD=/usr/pgsql-9.6/bin
export PGBINNEW=/usr/pgsql-12/bin
$PGBINNEW/pg_upgrade --link --verbose
# extrait du déroulement
mappings for database "prod":
public.pgbench_accounts: 16397 to 16391
linking "/var/lib/pgsql/9.6/data/base/16384/16397" to
"/var/lib/pgsql/12/data/base/16402/16391"
linking "/var/lib/pgsql/9.6/data/base/16384/16397_fsm" to
"/var/lib/pgsql/12/data/base/16402/16391_fsm"
linking "/var/lib/pgsql/9.6/data/base/16384/16397_vm" to
"/var/lib/pgsql/12/data/base/16402/16391_vm"
L’outil pg_upgrade est composé d’une série d’opération de contrôle, de copies
de fichiers, d’arrêt/démarrage des instances et d’une remise à zéro des journaux
de transactions avec pg_resetwal. Les lignes ci-dessus illustrent le mode
--link lors de notre migration, avec la création d’un lien entre les deux
versions du fichier de la table pgbench_accounts.
La méthode employée peut être consultée dans les sources de pg_upgrade et
repose sur la méthode link. Regardons en détail les métadonnées des
fichiers de données de la table pgbench_accounts dans les deux répertoires.
# FORMAT="${FORMAT}Links = %h\n"
# stat --printf="$FORMAT" /var/lib/pgsql/9.6/data/base/16384/16397
File = ‘/var/lib/pgsql/9.6/data/base/16384/16397’
Type = regular file
Owner = postgres:postgres
Access = -rw-------
Inode = 101132106
Links = 2
# stat --printf="$FORMAT" /var/lib/pgsql/12/data/base/16402/16391
File = ‘/var/lib/pgsql/12/data/base/16402/16391’
Type = regular file
Owner = postgres:postgres
Access = -rw-------
Inode = 101132106
Links = 2
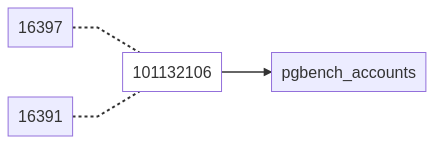
Au niveau du système, les fichiers sont strictement similaires. Pour dire vrai,
il s’agit des mêmes inodes. Les métadonnées sont communes aux deux fichiers et
les blocs de données de la table pgbench_accounts résident à la même adresse
physique.
À la différence du lien symbolique, ce type de lien rattache un fichier non pas
à un autre fichier, mais au numéro d’inode d’un autre fichier. L’attribut
Links de ma commande stat correspond au nombre de liens sur l’inode en
question. Une représentation de cette relation pourait être la suivante :
Les avantages sont doubles dans le cas d’une migration majeure :
- Temps de copie des données quasi-nul : le modèle de données est importé dans la nouvelle instance et les fichiers de données sont liés à ceux de la version précédente ;
- Économie d’espace disque : la migration n’a pas besoin du double d’espace disque.
En contrepartie :
- Pas de retour arrière : chacune des deux instances disposent de fichiers internes comme les journaux de transactions ou le fichier de contrôle, rendant incompatibles les fichiers de données à l’une des deux instances dès lors que l’autre a démarré après la migration.
Fin de vie d’une donnée liée
L’une de mes questions à l’issue d’une migration par pg_upgrade a été : « Mais
que se passe-t-il si nous ne supprimons pas l’ancien répertoire de données ? ».
Puisque la donnée est référencée par la nouvelle instance, toutes les nouveautés
y seront stockées et il n’y a pas de risque pour l’espace disque. Vraiment ?
Comme nous le voyions précédemment, les données de la table pgbench_accounts
sont accessibles à travers le numéro d’inode 101132106. Les deux liens
pointent vers la même adresse physique et la même allocation d’espace disque,
ici 13 Mo.
# du -lh 9.6/data/base/16384/16397 12/data/base/16402/16391
13M 9.6/data/base/16384/16397
13M 12/data/base/16402/16391
Il est possible au cours de la vie d’une table de voir son identifiant relfilenode
varier au moment de la réécriture du fichier sous un nom différent. Le cas se
présente lorsque l’on souhaite déplacer la table dans un autre tablespace,
quand il faut la défragmenter avec VACUUM FULL, ou lors de la restauration
d’un dump. Ces opérations réalisent toute une reconstruction de la table, avec
le déplacement des lignes dans un nouveau fichier.
SELECT pg_relation_filepath('pgbench_accounts');
-- pg_relation_filepath
-- ----------------------
-- base/16402/16391
VACUUM FULL pgbench_accounts;
CHECKPOINT;
SELECT pg_relation_filepath('pgbench_accounts');
-- pg_relation_filepath
-- ----------------------
-- base/16402/16435
Ici, la défragmentation reconstruit la table dans un nouveau fichier 16435.
L’instruction CHECKPOINT permet d’écrire sur disque la totalité des nouveaux
blocs et d’actualiser l’usage des fichiers, supprimant en principe les anciens
fichiers de données.
# du -lh 9.6/data/base/16384/16397 12/data/base/16402/16435
0 9.6/data/base/16384/16397
13M 12/data/base/16402/16435
# FORMAT="File = %n\nInode = %i\n"
# stat --printf="$FORMAT" 9.6/data/base/16384/16397
File = 9.6/data/base/16384/16397
Inode = 101132106
# stat --printf="$FORMAT" 12/data/base/16402/16435
File = 12/data/base/16402/16435
Inode = 34082173
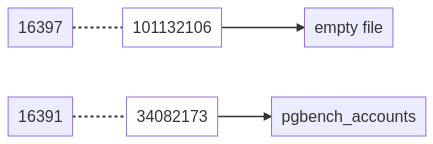
Le nouveau fichier de notre table pour l’instance 12 pèse toujours 13 Mo, le
fichier maintenu par le lien physique de la version précédente a été vidé lors
de l’opération VACUUM FULL et pèse à présent zéro octet. Mais il n’a pas été
supprimé ! Nous nous retrouvons avec un fichier et son inode en trop sur le
serveur.
Sur un système de fichiers, le nombre maximal de fichiers que l’on peut créer est
défini par la quantité d’inodes disponibles, alors autant faire le ménage dès
que possible pour ne pas atteindre cette limite. D’autant plus que la suppression
du répertoire 9.6/data est proposée à la fin de la migration par l’outil
pg_upgrade et ne présente aucun risque !
Conclusion
Apparu en version 9.0, l’outil pg_upgrade est une petite usine qui simule un
import/export des structures d’une instance complète, avec la capacité de copier
ou lier les anciens fichiers, de façon bien plus rapide qu’une insertion massive
avec l’instruction COPY de pg_restore. C’est une solution de choix lorsque
l’on migre d’une version majeure à l’autre sur un même serveur, notamment pour
le gain de temps non négligeable que propose l’option --link.
Avec la version 12, l’outil propose une nouvelle option --clone et s’appuie
sur la notion de liens « par référence » (ou reflinks), conçus initialement
sur les systèmes de fichiers supportant la copie sur écriture. La
documentation précise que la copie des fichiers est pratiquement instantanée et
n’affecte pas l’ancienne instance.
Peut-être l’occasion de creuser le sujet dans un prochain article ?