Tour d'horizon de PgBouncer
- 6 minutes de lecture
Les programmes de regroupement de connexions (pooling) vous permettent de réduire la surcharge liée à la base de données lorsque le nombre de connexions physiques réduit les performances. Ceci est particulièrement pertinent sous Windows, où les limitations du système empêchent un grand nombre de connexions. C’est également vital pour les applications Web où le nombre de connexions peut devenir très important.
(Source : https://wiki.postgresql.org)
Je n’ai pas trouvé meilleure approche que la traduction du wiki communautaire du projet PostgreSQL pour aborder l’outil PgBouncer, faisant partie avec Pgpool-II, des deux seuls poolers de connexions largement répandus. Le produit est déconcertant de facilité, sa documentation et la littérature qui gravitent sur Internet sont claires et unanimes : PgBouncer améliorera grandement les performances de votre instance PostgreSQL !
Dans cet article, je vous propose un rapide aperçu de PgBouncer avec quelques cas possibles d’utilisation. Nous parlerons aussi du récent support de l’authentification SCRAM et comment le configurer sans effort.
Théorie, ma vieille amie
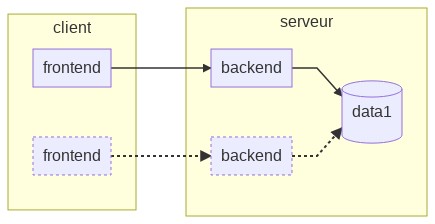
Depuis ses origines, le fonctionnement de PostgreSQL repose sur le modèle client/serveur multi-processus, c’est-à-dire que chaque processus aura une tâche définie et une zone mémoire qui lui est propre. Ce modèle s’oppose à l’architecture multi-thread dans laquelle un processus peut être partagé par plusieurs instructions indépendantes et présenterait des risques de corruptions de mémoire.
Ainsi, pour chaque demande de connexion vers l’instance, le processus
principal postgres se charge de l’authentification avant de créer un nouveau
processus backend qui maintiendra le lien entre les deux parties et assurera
l’aboutissement des commandes du processus client, appelé frontend. Le
backend ne sera libéré qu’à la déconnexion de la session utilisateur, comme
l’illustre le schéma ci-après.
Cependant, l’établissement de la connexion n’est pas une opération anodine. Les coûts des échanges à travers le réseau, de création d’un processus, de l’allocation de sa mémoire et du paramétrage de la session, représenteraient une poignée de millisecondes.
Comme indiqué en préambule, les applications critiques telles que celles du e-commerce requièrent des temps de réponses les plus faibles possibles, avec des exigences de l’ordre d’une centaine de millisecondes par appel de page, contenant elles-mêmes des centaines de requêtes… C’est à ce moment-là que PgBouncer entre en jeu.
Le schéma précédent évolue avec le pooler de connexions entre les connexions
clientes et l’instance de base de données. Le processus pgbouncer est donc
responsable des demandes entrantes et se comporte comme un proxy, qu’il soit sur
le serveur hébergeant les données, sur les serveurs frontaux ou même sur un
serveur tiers, dédié à ces redirections.
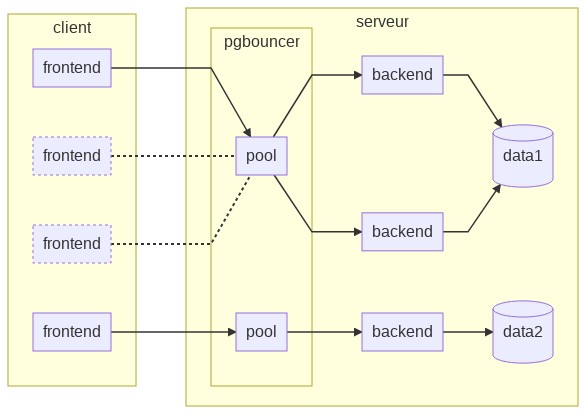
PgBouncer ne présente qu’une faible empreinte mémoire équivalente à 2 ko par connexion et repose sur un binaire et un fichier de configuration. L’outil gère des pools de connexions par bases de données ou par rôles (ou les deux) et maintient un certain nombre de connexions actives vers l’instance pour les recycler en cas d’arrivée de nouveaux frontends.
La configuration est extrêmement simple et épurée, et ne devrait rebuter personne.
Par exemple, en supposant que l’instance PostgreSQL écoute localement sur le port
5433 et dispose d’une base data1, nous cherchons à définir un pool de 5 à 50
backends avec un délai de 30 secondes d’inactivité avant la déconnexion réelle
au serveur. Le fichier de configuration suivant est alors parfaitement adapté :
[pgbouncer]
listen_addr = demo.priv
listen_port = 5432
auth_file = userlist.txt
server_idle_timeout = 30
min_pool_size = 5
[database]
data1 = host=localhost port=5433 dbname=data1 pool_size=50
Chérie, tu as les clés ?
Puisque PgBouncer fait office de proxy entre les applications et les bases de
données en respectant le protocole de connexion, il lui revient d’assurer la
validation des mots de passe de chaque nouvelle demande entrante. L’implémentation
des différentes méthodes telles que md5 ou scram-sha-256 se trouve dans le
fichier src/proto.c(source) et garantit qu’une demande de connexion réalisée sur
l’interface de PgBouncer soit bien légitime et autorisée auprès de l’instance.
Fichier auth_file
À ce sujet, l’outil propose deux solutions pour vérifier un mot de passe. La plus
basique consiste à renseigner un fichier (ou auth_file) avec les couples
login/password qui seront consultés à chaque demande, et les comparer avec les
éléments de l’utilisateur. Les données doivent être identiques aux informations
stockées dans l’instance PostgreSQL, plus précisément dans la relation système
pg_authid, ou historiquement pg_shadow.
SET password_encryption = 'scram-sha-256';
CREATE ROLE frontend PASSWORD 'pass' LOGIN;
SELECT rolpassword FROM pg_authid WHERE rolname = 'frontend' \gx
-- -[ RECORD 1 ]----------------------------------------------------
-- rolpassword | SCRAM-SHA-256$4096:e2iH7Tv/XJrD0bxiSNt4yA==$Pxhbz2…
L’ajout d’une nouvelle ligne dans le fichier userlist.txt nécessite uniquement
de prendre soin d’entourer chaque mot par des guillemets doubles. PgBouncer
surveillera alors son contenu afin de disposer des bonnes informations à tout
moment.
# userlist.txt
"frontend" "SCRAM-SHA-256$4096:e2iH7Tv/XJrD0bxiSNt4yA==$Pxhbz2…"
Délégation auth_user
Si la maintenance d’un tel fichier s’avère complexe pour quelque raison que ce
soit, il est possible de déléguer un rôle à la consultation de la table pg_authid
directement dans l’instance, en précisant le paramètre auth_user. Le paramètre
auth_query définit la requête à exécuter pour ensuite comparer les résultats
avec les identifiants de connexion. Cette requête repose sur la vue pg_shadow
mais de nombreuses variantes sont possibles, comme une requête plus élaborée sur
pg_authid ou une fonction qui dispose des bons droits de consultation avec
la clause SECURITY DEFINER comme le suggère la documentation.
Le support de la méthode d’authentification par SCRAM est arrivé avec la version
PgBouncer 1.14 en juin 2020. Le mot de passe chiffré avec SCRAM ne peut pas être
utilisé pour de la délégation de connexion, tel que le propose le paramètre
auth_user. L’un des contournements consiste à hacher le mot de passe en md5
pour le rôle de délégation.
SET password_encryption = 'md5';
CREATE ROLE admin SUPERUSER PASSWORD 'pass' LOGIN;
SELECT rolpassword FROM pg_authid WHERE rolname = 'admin' \gx
-- -[ RECORD 1 ]------------------------------------
-- rolpassword | md57a25b0bc04e77a2f7453dd021168cdc2
Le fichier userlist.txt ne contiendra donc qu’une seule ligne pour le rôle
admin défini comme auth_user dans la configuration PgBouncer.
# userlist.txt
"admin" "md57a25b0bc04e77a2f7453dd021168cdc2"
[pgbouncer]
listen_addr = demo.priv
listen_port = 5432
auth_type = scram-sha-256
auth_file = userlist.txt
auth_user = admin
;auth_query = SELECT usename, passwd FROM pg_shadow WHERE usename=$1
[database]
data1 = host=localhost port=5433 dbname=data1
Côté client, l’illusion est parfaite ! Le rôle frontend se connecte à l’instance
sans besoin d’ajouter ses identifiants dans le fichier userlist.txt.
$ psql "host=priv.demo dbname=data1 user=frontend"
Password for user frontend:
psql (12.4)
Type "help" for help.
data1=> \conninfo
You are connected to database "data1"
as user "frontend" on host "priv.demo" at port "5432".
Vers l’infini et au-delà
PgBouncer est un outil à connaître et à déployer sans modération pour la recherche de performance. Il se couple parfaitement bien avec une configuration HAProxy pour une architecture de haute-disponibilité si le besoin se fait sentir. Le support de l’authentification SCRAM est une excellente avancée, alors que la communauté se décide de la définir comme un standard pour les prochaines versions majeures de PostgreSQL.
D’autres fonctionnalités essentielles n’ont volontairement pas été abordées dans
cet article, comme le pooling de transactions et le paramètre pool_mode, ou
simplement la pseudo-base pgbouncer qui joue le rôle de console d’administration
très fournie en informations sur les pools et sessions actives. Gageons que
j’y passe plus de temps à l’avenir pour vous les présenter !