La brêve histoire du fichier backup_label
- 12 minutes de lecture
Je suis resté longtemps ignorant des mécanismes de journalisation et de PITR avec PostgreSQL alors même qu’il s’agit d’un des fonctionnements critiques pour la durabilité des données d’une instance. Mieux comprendre ces concepts m’aurait permis à une époque, d’être plus serein lors de la mise en place de sauvegardes et surtout au moment de leur restauration !
Dans cet article, je vous propose de revenir sur un fichier anecdotique qui a
fait parlé de lui pendant plusieurs années : le fichier backup_label.
Qui est-il et à quoi sert-il ? Comment a-t-il évolué depuis sa création en
version 8.0 de PostgreSQL et qu’adviendra-t-il de lui dans les prochaines années ?
Il était une fois la journalisation
En guise d’introduction pour mieux comprendre cet article, il est bon d’expliquer
que chaque opération d’écriture dans PostgreSQL comme un UPDATE ou un INSERT,
est écrite une première fois au moment du COMMIT de la transaction dans un groupe
de fichiers, que l’on appelle WAL ou journaux de transactions. Ajoutées les
unes à la suite des autres, ces modifications représentent un faible coût pour
l’activité des disques par rapport aux écritures aléatoires d’autres processus
de synchronisation à l’œuvre dans PostgreSQL.
Parmi l’un d’eux, le processus checkpointer s’assure que les nouvelles données
en mémoire soient définitivement synchronisées dans les fichiers de données à des
moments réguliers que l’on appelle CHECKPOINT. Cette écriture en deux temps sur
les disques apporte d’excellentes performances et garantit qu’aucun bloc modifié
ne soit perdu lorsqu’une transaction se termine correctement.
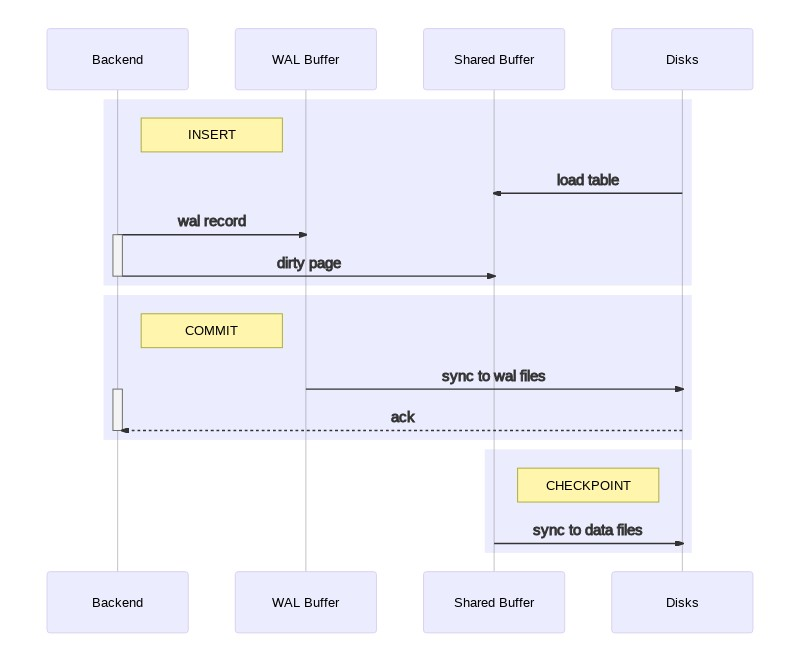
Par ce mécanisme de journalisation, les fichiers de données de notre instance
sont constamment en retard sur la véritable activité transactionnelle, et ce,
jusqu’au prochain CHECKPOINT. En cas d’arrêt brutal du système, les blocs en
attente de synchronisation (dirty pages) présents dans la mémoire Shared Buffer
sont perdus et les fichiers de données sont dit incohérents car ils mixent
des données de transactions anciennes, nouvelles, valides ou invalides.
Dans pareilles situations, il est possible de redémarrer l’instance afin qu’elle rejoue les modifications dans l’ordre des transactions telles qu’elles avaient été écrites dans les WAL. Cette reconstruction des fichiers de données pour retrouver leur état consistant est sobrement appelée la récupération des données ou crash recovery.
Que ce soit à la suite d’un crash ou dans le cadre d’une restauration de sauvegarde, les fichiers de données doivent être cohérents pour assurer le retour du service et l’accès en écriture aux données. Quelle mauvaise surprise n’a-t-on pas lorsqu’une instance PostgreSQL interrompt son démarrage avec le message suivant :
PANIC: could not locate a valid checkpoint record
Il indique que l’instance a détecté une inconsistance dans les fichiers au moment de son démarrage et qu’elle échoue à trouver le point de reprise le plus proche de son état. Sans les journaux, la récupération échoue et s’arrête. À cet instant précis, vos nerfs et votre politique de sauvegarde sont mis à rude épreuve.
Pour le dire encore autrement : en l’absence des journaux de transactions ou de leurs archives, vos plus récentes données sont perdues.
… Et l’outil pg_resetwal ne les récuperera pas pour vous.
Entre en scène le backup_label
Après ce charmant avertissement, on considèrera que l’archivage des journaux de transactions n’est plus une option dans vos plans de sauvegarde. Assurez-vous que ces archives soient stockées sur un espace sécurisé, voire une zone décentralisée pour qu’elles soient accessibles par toutes les instances secondaires lorsque vous devez déclencher votre plan de bascule.
Pour ceux ayant atteint cette partie de l’article, vous ne devriez pas être
trop perdus si je vous annonce que le fichier backup_label est un composant
d’un plus large concept, à savoir : la sauvegarde.
Le fichier historique de sauvegarde est un simple fichier texte. Il contient le label que vous avez attribué à l’opération
pg_basebackup, ainsi que les dates de début, de fin et la liste des segments WAL de la sauvegarde. Si vous avez utilisé le label pour identifier le fichier de sauvegarde associé, alors le fichier historique vous permet de savoir quel fichier de sauvegarde vous devez utiliser pour la restauration.Source : Réaliser une sauvegarde de base
Prenons une instance classique en cours d’exécution et réalisons une sauvegarde
avec l’outil pg_basebackup que nous vante la documentation. Observons son
comportement le plus simple avec la génération d’une archive au format tar.
$ pg_basebackup --label=demo --pgdata=backups --format=tar \
--checkpoint=fast --verbose
pg_basebackup: initiating base backup, waiting for checkpoint to complete
pg_basebackup: checkpoint completed
pg_basebackup: write-ahead log start point: 0/16000028 on timeline 1
pg_basebackup: starting background WAL receiver
pg_basebackup: created temporary replication slot "pg_basebackup_15594"
pg_basebackup: write-ahead log end point: 0/16000100
pg_basebackup: waiting for background process to finish streaming ...
pg_basebackup: syncing data to disk ...
pg_basebackup: renaming backup_manifest.tmp to backup_manifest
pg_basebackup: base backup completed
Depuis la version 10, l’option --wal-method est définie
sur stream par défaut, ce qui indique que tous les journaux de transactions
présents et à venir dans le sous-répertoire pg_wal de l’instance seront
également sauvegardés dans une archive dédiée, notamment grâce à la création
d’un slot de réplication temporaire.
Depuis la version 13, l’outil embarque le fichier manifeste dans la sauvegarde
afin de pouvoir contrôler l’intégrité de la copie par la commande
pg_verifybackup. Contrôlons le contenu du répertoire de sauvegarde et
recherchons le tant attendu backup_label.
$ tree backups/
backups/
├── backup_manifest
├── base.tar
└── pg_wal.tar
$ tar -xf backups/base.tar --to-stdout backup_label
START WAL LOCATION: 0/16000028 (file 000000010000000000000016)
CHECKPOINT LOCATION: 0/16000060
BACKUP METHOD: streamed
BACKUP FROM: master
START TIME: 2021-01-18 15:22:52 CET
LABEL: demo
START TIMELINE: 1
Ce dernier se trouve à la racine de notre archive et joue un rôle très
particulier dans le processus de démarrage startup puisqu’il renseigne le point
de reprise à partir duquel rejouer les journaux. Dans notre exemple, il s’agit
de la position 0/16000060 présente dans le journal 000000010000000000000016.
En cas d’absence du backup_label, le processus de démarrage consultera à la
place le fichier de contrôle afin de déterminer le plus récent point de
reprise sans garantie qu’il soit le bon.
L’heure de gloire
Vous conviendrez que la forme et l’intérêt du fichier backup_label sont
anecdotiques (bien qu’essentiels) dans l’architecture de sauvegarde avec PostgreSQL.
Il ne s’agit que d’un fichier texte de quelques lignes, requis exclusivement pour
assurer certains contrôles lors d’une restauration.
Et pourtant, la petite révolution que provoqua la version 8.0 en janvier 2005
avec l’archivage continu et la restauration PITR suscita naturellement la
créativité de l’équipe de développement au cours des années qui suivirent. Le
fichier backup_label évolua pour gagner en modularité et en stabilité.
À l’origine, l’outil pg_basebackup n’était pas encore disponible et seul l’appel
à la méthode pg_start_backup() permettait de générer le fichier dans lequel
se trouvaient les quatres informations suivantes pour accompagner la
sauvegarde à chaud :
# backend/access/transam/xlog.c
fprintf(fp, "START WAL LOCATION: %X/%X (file %s)\n",
startpoint.xlogid, startpoint.xrecoff, xlogfilename);
fprintf(fp, "CHECKPOINT LOCATION: %X/%X\n",
checkpointloc.xlogid, checkpointloc.xrecoff);
fprintf(fp, "START TIME: %s\n", strfbuf);
fprintf(fp, "LABEL: %s\n", backupidstr);
Les versions majeures se sont enchaînées avec son lot de corrections ou d’améliorations. Parmi les contributions notables, j’ai relevé pour vous :
Contribution de Laurenz Albe (commit c979a1fe)
Publié avec la version 8.4, le code
xlog.cse voit enrichir d’une méthode interne pour annuler la sauvegarde en cours. L’exécution de la commandepg_ctl stopen mode fast renomme le fichier enbackup_label.old;Contribution de Dave Kerr (commit 0f04fc67)
Apparue avec la version mineure 9.0.9, la méthode
pg_start_backup()inclut un appelfsync()pour forcer l’écriture sur disque du fichierbackup_label. Cette sécurité garantit la consistance d’un instantané matériel ;Contribution de Heikki Linnakangas (commit 41f9ffd9)
Proposé en version 9.2, ce patch corrige des comportements anormaux de restauration à partir de la nouvelle méthode de sauvegarde par flux. Le fichier
backup_labelprécise la méthode employée entrepg_start_backupoustreamed;Contribution de Jun Ishizuka et Fujii Masao (commit 8366c780)
Depuis la version 9.2, la méthode
pg_start_backup()peut être exécutée sur une instance secondaire. Le rôle de l’instance d’où provient la sauvegarde est renseignée dans le fichierbackup_label;Contribution de Michael Paquier (commit 6271fceb)
Ajoutée en version 11, l’information timeline dans le fichier
backup_labelrejoint les précédentes pour comparer sa valeur avec celles des journaux à rejouer lors d’une récupération de données ;
Vous l’aurez compris, pendant de nombreuses années, la capacité de faire une
sauvegarde dite consistante, reposait sur les deux méthodes vues précédemment.
La fonction historique pg_start_backup() fut particulièrement touchée
par d’incessantes critiques au sujet d’un comportement non souhaité, notamment
son mode « exclusif ».
Voyons cela ensemble sur une instance récente en version 13 :
SELECT pg_start_backup('demo');
-- pg_start_backup
-- -----------------
-- 0/1D000028
$ kill -ABRT $(head -1 data/postmaster.pid)
$ cat data/backup_label
START WAL LOCATION: 0/1D000028 (file 00000001000000000000001D)
CHECKPOINT LOCATION: 0/1D000060
BACKUP METHOD: pg_start_backup
BACKUP FROM: master
START TIME: 2021-01-18 16:49:57 CET
LABEL: demo
START TIMELINE: 1
Le signal ABRT interrompt sans préavis le processus postmaster de l’instance
et la routine d’arrêt CancelBackup n’est pas appelée pour renommer le fichier
en backup_label.old. Avec une activité classique de production, les journaux
sont recyclés et archivés à mesure que les transactions s’enchaînent. Au démarrage
de l’instance, le fichier backup_label présent dans le répertoire de données
est lu par erreur et n’indique plus le bon point de reprise pour la récupération
des données.
LOG: database system was shut down at 2021-01-18 17:08:43 CET
LOG: invalid checkpoint record
FATAL: could not locate required checkpoint record
HINT: If you are restoring from a backup, touch "data/recovery.signal"
and add required recovery options.
If you are not restoring from a backup, try removing the file
"data/backup_label".
Be careful: removing "data/backup_label" will result in a corrupt
cluster if restoring from a backup.
LOG: startup process (PID 19320) exited with exit code 1
LOG: aborting startup due to startup process failure
LOG: database system is shut down
Ce message complet n’est apparu qu’à partir de la version 12 avec un avertissement plus prononcé dans la documentation au sujet du fichier, faisant suite à de longs échanges sur la possibilité de se séparer ou non de cette méthode. Dans l’un d’eux, on peut lire la remarquable intervention de Robert Haas qui revient sur le succès de cette fonctionnalité depuis ses débuts et la confusion fréquente que rencontrent les utilisateurs qui ne comprennent ni la complexité ni les instructions claires de la documentation.
À présent, une note y clarifie les choses.
Ce type de sauvegarde peut seulement être réalisé sur un serveur primaire et ne permet pas des sauvegardes concurrentes. De plus, le fichier backup_label créé sur un serveur primaire peut empêcher le redémarrage de celui-ci en cas de crash. D’un autre côté, la suppression à tord de ce fichier d’une sauvegarde ou d’un serveur secondaire est une erreur fréquente qui peut mener à de sérieuses corruptions de données.
Place à la relève
Cette limitation était connue de longue date et l’équipe de développement proposa une alternative en septembre 2016 avec la sortie de la version 9.6 et l’introduction de la sauvegarde dite « concurrente ». Depuis ce jour, la sauvegarde exclusive est annoncée obsolète par les développeurs et pourrait être supprimée dans les versions à venir.
Le fichier backup_label ne disparaît pas en soi. Ses informations sont toujours
requises pour la restauration PITR mais le fichier n’a plus d’état transitoire sur
le disque et n’est plus écrit dans le répertoire de l’instance par la méthode
pg_start_backup(). En remplacement, l’administrateur ou le script de sauvegarde
doit être en capacité d’exécuter la commande pg_stop_backup() dans la même
connexion à l’instance pour y récupérer les éléments et reconstruire le fichier
au moment de la restauration.
SELECT pg_start_backup(label => 'demo', exclusive => false, fast => true);
-- pg_start_backup
-- -----------------
-- 0/42000028
SELECT labelfile FROM pg_stop_backup(exclusive => false);
-- labelfile
-- ----------------------------------------------------------------
-- START WAL LOCATION: 0/42000028 (file 000000010000000000000042)+
-- CHECKPOINT LOCATION: 0/42000060 +
-- BACKUP METHOD: streamed +
-- BACKUP FROM: master +
-- START TIME: 2021-01-18 18:17:16 CET +
-- LABEL: demo +
-- START TIMELINE: 1 +
Une autre méthode nous permet de retrouver facilement le contenu du fichier,
d’autant plus si l’archivage est en place sur l’instance. En effet, à l’annonce
de la fin d’une sauvegarde, les éléments précédents sont écrits dans un fichier
d’historique .backup au sein des journaux de transactions et un fichier .ready
est ajouté dans le répertoire archive_status à destination du processus
d’archivage. Une recherche rapide sur le dépôt des archives plus tard, et nous
sommes en possession du fichier prêt à l’emploi pour une restauration.
$ find archives -type f -not -size 16M
archives/000000010000000000000016.00000028.backup
$ grep -iv ^stop archives/000000010000000000000016.00000028.backup
START WAL LOCATION: 0/42000028 (file 000000010000000000000042)
CHECKPOINT LOCATION: 0/42000060
BACKUP METHOD: streamed
BACKUP FROM: master
START TIME: 2021-01-18 18:17:16 CET
LABEL: demo
START TIMELINE: 1
La venue d’une brique complète pour la sauvegarde concurrente a permis l’émergence
de nouvelles solutions de sauvegardes, plus performantes et plus modulaires que
pg_basebackup. Dans le paysage des outils tiers, vous entendriez peut-être parler
de pgBackRest écrit en C, Barman écrit en Python ou pitrery écrit en Bash.
En outre, ces outils soulagent l’administrateur de la rédaction de scripts devenus
trop complexes et loin d’être immuable dans les années à venir.
Morale de l’histoire
Au fil des versions, le fichier backup_label a enduré de nombreuses tempêtes
et rebondissements pour aboutir à une forme plus aboutie de la sauvegarde et de
la restauration physique dans PostgreSQL.
Si vous êtes responsable de la maintenance d’instances, particulièrement dans
un environnement virtualisé, je ne peux que vous recommander de contrôler vos
politiques de sauvegarde et l’outillage associé. Il n’est pas rare de voir des
hyperviseurs réaliser des instantanées des machines virtuelles avec des appels de
la méthode pg_start_backup() en mode exclusif.
Les outils spécialisés cités plus haut peuvent/doivent être étudiés. S’ils ne
correspondent pas très bien à vos besoins, il est toujours possible de
bénéficier des mécanismes de la sauvegarde concurrente à l’aide d’un fichier
temporaire sous Linux et sa commande mkfifo.
La décision de supprimer définitivement la sauvegarde exclusive n’est actuellement
plus débattue et a été retirée du backlog de développement lors du Commitfest
de juillet 2020. Lors des derniers échanges, le contributeur David Steele
(auteur de pgBackRest notamment) annonçait qu’une sauvegarde exclusive pourrait
stocker son fichier backup_label directement en mémoire partagée plutôt que sur
le disque et ainsi corriger sa principale faiblesse :
It might be easier/better to just keep the one exclusive slot in shared memory and store the backup label in it. We only allow one exclusive backup now so it wouldn’t be a loss in functionality.
La suite au prochain épisode !