Comprendre les requêtes préparées
- 8 minutes de lecture
Les requêtes ou instructions préparées sont un mécanisme proposé par la plupart des moteurs de bases de données afin de réexécuter un ordre SQL semblable au précédent. On parle d’un template de requête qu’il est nécessaire de préparer avant d’exécuter. Les principaux bénéfices que nous lui connaissons méritent un article afin de mieux comprendre leur implémentation.
Parse-Bind-Execute
Au cours de sa vie, tout bon artisan du Web finit par découvrir les ravages des attaques par injection SQL, soit par la sagesse de leurs mentors, soit par la douloureuse expérience du terrain. Bien que les nombreuses couches d’abstraction les rendent aujourd’hui inopérantes grâce aux échappements ou à la validation des données en entrée, ces attaques sont encore possibles dès que la requête est écrite en pur SQL.
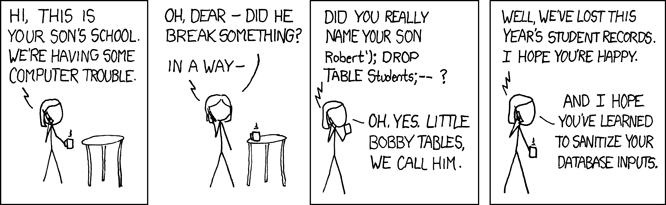
Source : https://xkcd.com/327
L’une des meilleures approches pour éviter ces attaques, repose sur la séparation des requêtes et de leurs paramètres au moment de leur exécution. L’instruction, dite préparée, est ainsi intégralement analysée et le positionnement des valeurs est connu à l’avance. Toute tentative d’injection est réduite à néant.
PREPARE get_notation(text, text) AS
SELECT id, exam, notation FROM students
WHERE lastname = $1 AND firstname = $2;
EXECUTE get_notation('Pattinson', $$Robert' ; DROP TABLE students;--$$);
-- (0 rows)
L’exemple précédent utilise les ordres SQL PREPARE et EXECUTE mais ce n’est
pas la seule façon de déclarer une instruction préparée. En effet, il existe à
ce sujet le sous-protocole Extended Query décrit dans la documentation sur les
flux de messages. La communication client-serveur se découpe en trois
messages afin de garantir la prise en compte des paramètres à inclure dans une
instruction préparée, sans risque d’injection.
- Parse : l’instruction SQL et éventuellement un nom et un typage pour les paramètres ;
- Bind : les valeurs à positionner dans l’instruction préparée donnée ;
- Execute : déclenche la lecture du curseur ouvert sur le serveur.
Il est donc de la responsabilité du pilote ou du connecteur fourni avec le
langage ou le framework de son choix, de proposer les méthodes de communication
qui s’appuient sur le bon protocole étendu. En C et avec la libpq par exemple
(doc), la déclaration d’une instruction préparée se réalise avec la méthode
PQprepare et l’exécution avec PQexecPrepared.
Côté serveur, si l’on étend la verbosité des traces d’activité avec les
paramètres log_parser_stats, log_planner_stats, log_executor_stats et
log_min_duration_statement, il est possible d’identifier les étapes citées plus
haut avec l’exécution d’une requête préparée par pgbench, nommée P0_1.
-- Message PARSE
LOG: PARSER STATISTICS
LOG: PARSE ANALYSIS STATISTICS
LOG: REWRITER STATISTICS
LOG: duration: 1.284 ms
parse P0_1: SELECT abalance FROM pgbench_accounts WHERE aid = $1;
-- Message BIND
LOG: PLANNER STATISTICS
LOG: duration: 1.211 ms
bind P0_1: SELECT abalance FROM pgbench_accounts WHERE aid = $1;
DETAIL: parameters: $1 = '1600439'
-- Message EXECUTE
LOG: EXECUTOR STATISTICS
LOG: duration: 4.170 ms
execute P0_1: SELECT abalance FROM pgbench_accounts WHERE aid = $1;
DETAIL: parameters: $1 = '1600439'
Quand un plan générique se déroule sans accroc
Cependant, la sécurité contre les injections n’est pas mise en avant dans la
documentation de PostgreSQL au sujet de PREPARE. Et pour cause, depuis son
implémentation dans la version 7.3, cette méthode repose sur des mécanismes
profonds pour optimiser les performances d’une requête lorsqu’elle est exécutée
un certain nombre de fois.
Les instructions préparées sont principalement intéressantes quand une seule session est utilisée pour exécuter un grand nombre d’instructions similaires. La différence de performances est potentiellement significative si les instructions sont complexes à planifier ou à réécrire, par exemple, si la requête implique une jointure de plusieurs tables ou requiert l’application de différentes règles. Si l’instruction est relativement simple à planifier ou à réécrire mais assez coûteuse à exécuter, l’avantage de performance des instructions préparées est moins net.
Avec PostgreSQL, chaque requête passe par une succession d’étapes pour obtenir le résultat final. Ce fonctionnement permet de qualifier la transformation d’une étape à une autre en s’assurant par ailleurs que la syntaxe est bonne ou qu’un chemin optimisé puisse être emprunté.
- Le parser vérifie la syntaxe de l’instruction, ouvre une transaction pour réaliser l’analyse sémantique auprès des relations voulues ;
- Le rewriter réalise les transformations nécessaires en fonction des règles telle que la définition d’une vue ou d’une fonction ;
- Le planner (ou planificateur) sélectionne le plan d’exécution le moins coûteux en fonction des régles d’accès et des estimations connues ;
- L’executor suit les consignes du plan d’exécution et consolide le résultat final à retourner au client.
Les étapes d’analyse d’une instruction lors des messages Parse et Bind ont un
coût : il est nécessaire de valider la syntaxe, réécrire les jointures si besoin
et surtout, construire le plan d’exécution. Par défaut, une série de plans sera
construit avant que le moteur n’en retienne qu’un seul dont le coût est bon
compromis avec la moyenne des cinq premiers. Ce plan devient le plan générique
et sera réutilisé au sein de la même session pour toutes les exécutions de
l’instruction préparée.
L’utilisation de ce plan d’exécution unique devient la clé pour économiser
quelques précieuses millisecondes d’analyse à chaque nouveau message Execute.
Si je reprends l’exemple de Bobby et de la table students, on observe un gain
significatif au bout de la cinquième ou sixième exécution avec un temps de
planification (Planning Time) quasi-nul.
EXPLAIN (ANALYZE)
EXECUTE get_notation('Pattinson', 'Robert');
-- QUERY PLAN
-- -------------------------------------------------------------------------------
-- Index Scan using students_lastname_firstname_idx on students
-- (cost=0.29..6.06 rows=1 width=13) (actual time=0.027..0.029 rows=1 loops=1)
-- Index Cond: ((lastname = 'Pattinson'::text) AND (firstname = 'Robert'::text))
-- Planning Time: 0.235 ms
-- Execution Time: 0.071 ms
-- ...
-- Planning Time: 0.225 ms
-- Execution Time: 0.090 ms
-- ...
-- Planning Time: 0.323 ms
-- Execution Time: 0.081 ms
-- ...
-- Planning Time: 0.249 ms
-- Execution Time: 0.074 ms
-- ...
-- Planning Time: 0.218 ms
-- Execution Time: 0.068 ms
-- ...
-- Planning Time: 0.232 ms
-- Execution Time: 0.068 ms
-- ...
-- Planning Time: 0.040 ms
-- Execution Time: 0.091 ms
-- ...
-- Planning Time: 0.036 ms
-- Execution Time: 0.089 ms
Depuis la version 12 de PostgreSQL, il est possible de changer le comportement
du moteur avec le paramètre plan_cache_mode en forçant l’utilisation du plan
générique dès la deuxième exécution (force_generic_plan) ou ne pas l’utiliser
du tout (force_custom_plan).
Les dessous du temps de réponse
Pour se convaincre des bénéfices qu’engendre l’utilisation des instructions préparées,
j’ai souhaité étudier le comportement d’une même requête SELECT sur la table
pgbench_accounts. L’outil pgbench fourni avec le projet PostgreSQL permet de
générer une variété de requêtes sur un modèle de données générique.
export PGDATABASE=pgbench
pgbench --initialize --scale=100
La table contient 10 millions de lignes et dispose d’une clé primaire sur laquelle nous estimerons qu’une grande partie des requêtes réalisera ses lectures. J’active également les paramètres pour tracer les statistiques de chacune des étapes citées plus haut, afin d’en savoir plus sur leur durée respective et la répartition du temps de travail entre elles.
PGOPTIONS="-c client_min_messages=log"
PGOPTIONS="$PGOPTIONS -c log_parser_stats=on"
PGOPTIONS="$PGOPTIONS -c log_planner_stats=on"
PGOPTIONS="$PGOPTIONS -c log_executor_stats=on"
export PGOPTIONS
Ces informations statistiques de l’ensemble des requêtes de pgbench sont
redirigées de la sortie d’erreurs vers une routine awk qui agrège les temps
de traitement. Dans cette démonstration, le paramètre plan_cache_mode est
positionné sur auto, sa valeur par défaut.
- Exécution sans préparation
pgbench --protocol=simple --select-only --transactions=10000 \
2>&1 >/dev/null | awk '
/STATISTICS/ { $1="" ; k=$0 }
/elapsed/ { stats[k]+=$8 ; count[k]+=1 ; total+=$8 }
END { for (s in stats) printf "%s: %1.3f ms\n", s, stats[s]*1000 }
END { printf " -- TOTAL: %1.3f ms\n", total*1000 }'
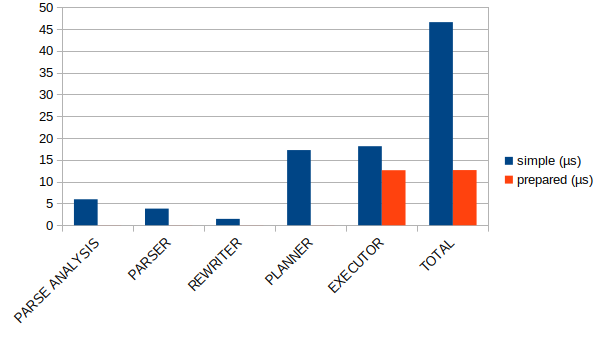
EXECUTOR STATISTICS: 163.910 ms
PARSE ANALYSIS STATISTICS: 57.493 ms
PLANNER STATISTICS: 163.451 ms
PARSER STATISTICS: 37.018 ms
REWRITER STATISTICS: 13.753 ms
-- TOTAL: 435.625 ms
- Exécution avec préparation
pgbench --protocol=prepared --select-only --transactions=10000 \
2>&1 >/dev/null | awk '
/STATISTICS/ { $1="" ; k=$0 }
/elapsed/ { stats[k]+=$8 ; count[k]+=1 ; total+=$8 }
END { for (s in stats) printf "%s: %1.3f ms\n", s, stats[s]*1000 }
END { printf " -- TOTAL: %1.3f ms\n", total*1000 }'
EXECUTOR STATISTICS: 157.778 ms
PARSE ANALYSIS STATISTICS: 0.746 ms
PLANNER STATISTICS: 1.146 ms
PARSER STATISTICS: 0.129 ms
REWRITER STATISTICS: 0.031 ms
-- TOTAL: 159.830 ms
Rapporté à une exécution unitaire, la répartition des temps de traitement entre les phases de préparation et d’exécution est sans surprise. Alors que le temps de préparation (Parse, Rewrite, Plan) est supérieur au temps d’exécution pour des instructions non préparées, il s’annule intégralement sur un volume de plusieurs milliers de requêtes exécutées dans la même session avec l’utilisation d’un plan générique.
Pour aller plus loin
Que ce soit pour se protéger des injections ou pour atteindre de hautes performances, j’ai voulu montrer dans cet article qu’il pouvait être bénéfique de préparer ses requêtes, d’autant plus si votre librairie préférée le supporte. Si vous êtes à la recherche de temps de réponse les plus faibles possibles, posez-vous les questions suivantes :
- Mes requêtes ont-elles fréquemment la même forme ?
- Leurs plans d’exécution sont-ils relativement bien optimisés ?
- Mon application gère-t-elle la persistance des connexions ?
Si vous rentrez dans ces cases, vous gagnerez de précieuses millisecondes avec un plan générique au sein d’une même session. Dans le cas où la persistance des connexions n’est pas votre fort, il est possible de coupler PgBouncer avec l’extension preprepare pour définir un ensemble d’instructions préparées dès l’ouverture de la session.