Parlons un peu des données externes
- 7 minutes de lecture
Depuis plusieurs semaines, j’étudie les nouveautés de la prochaine version majeure de PostgreSQL avec un intérêt grandissant pour le connecteur postgres_fdw. Cette extension assez folle n’a pas son équivalent sur les autres systèmes de bases de données du marché, et pour cause, PostgreSQL est l’un des rares à respecter la norme SQL/MED, sous-partie du langage SQL tel que défini par le standard ISO/IEC 9075-9.
Un langage pour les gouverner tous
Il y a maintenant plus d’un demi-siècle que fut conçu le langage SQL, fruit de la collaboration de deux chercheurs, Donald D. Chamberlin et Ray Boyce, dans la lancée des innovations des années 70, tel que le modèle relationnel. Ces deux personnages souhaitaient à l’époque proposer un outil de requêtage relationnel qui pourrait être accessible au plus grand nombre, dans une langue universelle et sans formation particulière en mathématique ou en programmation logicielle.
Alors que Ray Boyce mourut prématurément à l’âge de 26 ans, la notoriété de leur langage s’amplifia lors de sa phase de développement chez IBM et le sobrement nommé « Sequel » changea de nom en conflit avec une autre marque déposée. Ainsi le nom du projet fut raccourci en « SQL » à l’aube de l’année 1977. La décennie qui suivit fut marquée par l’émergence des produits comme Oracle Database et DB2, implémentant alors les prémices du SQL que l’on connait aujourd’hui.
En 1986, le langage évolua sous la forme d’un standard, repris par les regroupements ANSI et ISO, afin de promouvoir les règles d’écriture et la conformité auprès des différents éditeurs. Les standards ANSI X3.135 et ISO/IEC 9075 étaient nés. À partir de ce point précis, et les nombreuses révisions du standard SQL, les utilisateurs avaient l’assurance de ne pas être dépendants d’un unique éditeur logiciel, bien que certains ne répondaient pas à la totalité du standard et intégraient volontiers des fonctionnalités propriétaires.
C’est lors de la révision de l’année 2003 que le standard fut subdivisé en 9 parties issues du standard précédent. Chacune d’entre elles ayant pour ambition de couvrir un aspect différent du langage et parmi elles, nous retrouvons celle qui m’intéresse particulièrement ces temps-ci : la norme ISO/IEC 9075-9, Management of External Data, aussi appelée SQL/MED.
Ce chapitre de la norme propose les concepts de datalink et de foreign-data wrapper, ainsi que les différentes syntaxes pour les manipuler. Ces éléments peuvent déjà vous paraître familiers, il s’agit de la même terminologie qu’emploie PostgreSQL pour répondre à la norme. Ce standard impliquerait que les données d’un système soient dites externes, si elles sont disponibles et gérés par un autre système de base de donnée.
Une telle architecture répondant à ces contraintes permet l’émergence des systèmes de bases de données fédérées, responsables de la gestion d’un ensemble de données autonomes et hétérogènes. Sur le plan théorique, les utilisateurs et les applications ne se connectent plus qu’à un seul point d’accès et seraient capables de consulter et modifier les données éparpillées sur différents moteurs de bases de données.
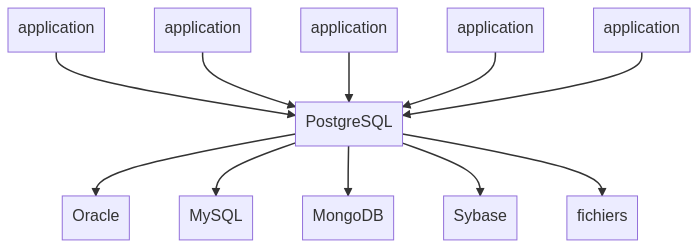
Pour garantir un tel résultat, la norme SQL/MED articule autours des connecteurs (wrappers), une série de composant tels que les serveurs distants (foreign servers) ou les correspondances d’utilisateurs (user mappings). Ainsi, chaque connecteur s’appuie sur une librairie logicielle pour permettre la communication avec le serveur à l’aide de ces identifiants de connexion.
Au cours des années qui suivirent, la communauté de développeurs autours de PostgreSQL s’est aligné avec la norme pour proposer plusieurs extensions stables de connecteurs. Aujourd’hui, la plupart des systèmes relationnels disposent d’une abstraction pour permettre l’accès des données externe à l’intérieur de PostgreSQL.
Une implémentation aux petits oignons
Avec un cycle de développement annuel et le support d’une version majeure sur une durée de cinq années, les grands chantiers ont fréquemment été menés par petits pas. L’implémentation de SQL/MED dans PostgreSQL n’y a pas fait exception.
C’est en juillet 2009 que sort la version 8.4, la dernière de la branche 8.x
avant l’avènement des versions plus récentes. L’architecture qui rendrait possible
les connecteurs avait été posée. Le catalogue fut enrichi par de nouvelles vues,
telles que pg_foreign_data_wrapper, pg_foreign_server ou pg_user_mapping et
de nouvelles commandes préparaient le terrain.
CREATE FOREIGN DATA WRAPPER postgresql;
CREATE SERVER demo FOREIGN DATA WRAPPER postgresql OPTIONS (dbname 'demo');
CREATE USER MAPPING FOR public SERVER demo;
La gestion des données distantes n’était alors possible qu’à travers l’extension
dblink qui fut rendue compatible avec les nouveaux objets de la norme SQL/MED.
L’exemple ci-dessous s’appuie sur le serveur demo avec une connexion préalable
à l’aide de la méthode dblink_connect. À cette époque, les connecteurs reposaient
sur la libpq par défaut.
-- les extensions n'existent pas encore en version 8.4 :-)
\i src/contrib/dblink/dblink.sql
SELECT dblink_connect('myconn', 'demo');
-- dblink_connect
-- ----------------
-- OK
SELECT *
FROM dblink('myconn', 'SELECT word FROM messages')
AS t(hello text);
-- hello
-- -------
-- world
Le projet pl/proxy profita également de ces améliorations pour définir un cluster
de serveurs distants sur lesquels il était possible d’exécuter des fonctions
déportées, et d’envisager une architecture éclatée (sharding) sur plusieurs
instances PostgreSQL.
En septembre 2011, les choses s’accélérèrent à la sortie de PostgreSQL 9.1 avec
l’ajout des tables distantes (ou foreign tables) pour compléter le chantier
initié par la version 8.4. Bien qu’elles n’étaient accessibles qu’en lecture seule,
leur fonctionnement faisait pâlir dblink à bien des égards.
Derrière chaque table distante se cache un connecteur, préalablement configuré
avec ses informations d’accès et d’authentification. En plus du wrapper interne
pour les instances PostgreSQL, la contribution file_fdw fut ajoutée au projet
afin d’autoriser les fichiers CSV et COPY comme sources de données externes. Ce
type de table est similaire aux tables externes qu’Oracle propose pour les
formats CSV, Datapump ou SQL*Loader.
CREATE EXTENSION file_fdw;
CREATE SERVER file_server FOREIGN DATA WRAPPER file_fdw;
CREATE FOREIGN TABLE departments (
department_id int,
department_name varchar(30) NOT NULL
) SERVER file_server OPTIONS (
filename '<path>/departments.dat'
);
Sur pareilles tables, PostgreSQL supporte uniquement les contraintes (NOT) NULL
et CHECK pour des besoins de planification. Ces contraintes doivent être assurées
par le serveur distant. Les clés primaires ou contraintes UNIQUE impliquent la
création d’un index, qui ne sont pas supportés pour les tables distantes.
CREATE INDEX ON departments (department_id);
-- ERROR: cannot create index on foreign table "departments"
L’usage premier des tables distantes consiste à intégrer ces relations dans les
requêtes SQL comme de simples tables, ce qui vous l’avouerez, reste bien plus
simple que d’écrire des sous-requêtes avec les résultats par dblink. Par ailleurs,
le nœud Foreign Scan fait son introduction pour représenter la lecture distante
à travers le connecteur.
EXPLAIN (analyze, costs off)
SELECT department_name, count(employee_id)
FROM employees JOIN departments USING (department_id)
WHERE department_id = 1
GROUP BY department_name;
QUERY PLAN
-----------------------------------------------------------------------
HashAggregate (actual time=0.084..0.084 rows=1 loops=1)
-> Nested Loop (actual time=0.058..0.077 rows=1 loops=1)
-> Foreign Scan on departments
(actual time=0.034..0.050 rows=1 loops=1)
Filter: (department_id = 1)
Foreign File: departments.dat
-> Index Scan using employees_department_id_idx on employees
(actual time=0.020..0.022 rows=1 loops=1)
Index Cond: (department_id = 1)
Total runtime: 0.230 ms
Conclusion
La page pgpedia sur les FDW reprend l’historique des améliorations apportées entre chaque version majeure depuis une décennie. Le travail abattu est impressionnant et se poursuit encore avec la prochaine version. L’architecture pensée lors de la version 8.4 reste toujours fiable, robuste et aura permis l’émergence de nombreux connecteurs pour PostgreSQL (postgres_fdw), Oracle (oracle_fdw) ou SQL Server (tds_fdw).
Parmi les nombreuses possibilités qu’apporte la norme SQL/MED, j’ai pu apprécier récemment l’usage du connecteur Oracle dans la version 22.0 de l’outil Ora2Pg pour les migrations de données grâces aux tables distantes. Avec la version 14 de PostgreSQL, la lecture asynchrone des partitions distantes permettra d’accélérer passablement les requêtes d’analyse sur de fortes volumétries.