Migrer vers PostgreSQL
- 10 minutes de lecture
Le marché de la migration en France est intense. Le Groupe de Travail Inter-Entreprises PostgreSQL (PGGTIE) a même publié un guide de transition à PostgreSQL à destination des entreprises françaises. Ce dernier est le fruit de près de cinq années de travaux au sein de plusieurs organismes publics et a pour ambition de démontrer l’intérêt de PostgreSQL aux décideurs techniques en présentant les forces et les faiblesses du moteur.
Le mois dernier, une traduction en anglais est sortie des cartons pour promouvoir davantage ce mouvement vers le logiciel libre dans les autres pays. Je trouvais intéressant de profiter de cette actualité pour partager mes réflexions du moment, entre ma vision du marché français et l’approche technique pour engager les migrations de données vers PostgreSQL.
Une transition à marche forcée
La démarche n’est pas anodine, car depuis 2012, l’État français au travers de ses différents ministères, tente de contrer l’imposant marché des logiciels propriétaires en favorisant leurs remplacements systématiques par une alternative Open Source. Depuis quelques années, le Socle Interministériel de Logiciels Libres (SILL) est mis à jour par un groupe de travail pour faire un bilan des choix structurants engagés sur le territoire français.
La publication d’un guide de transition pour PostgreSQL aspire à rassurer les équipes opérationnelles et décisionnelles en apportant un grand nombre de conseils et de comparaisons sur ce qu’il est aujourd’hui possible de faire avec PostgreSQL. Il mentionne les trois grandes étapes pour réaliser la migration des données d’une application vers le moteur open-source :
- migration des données ;
- correction et réécriture des requêtes SQL et des procédures embarquées ;
- recette du système pour écarter les régressions fonctionnelles.
Chacune de ces étapes a un coût, qu’il sera nécessaire de pondérer durant le chantier de migration. Les logiciels Open Source sont libres, mais ne sont pas gratuits et c’est un rappel essentiel que proposent les conclusions de ce guide. Les coûts de formation et de prestations externes ne sont également pas négligeables…
En 2018, la société française Dalibo avait publié un livre blanc dans ce même esprit de pédagogie sur l’importance des coûts d’investissement et de possession. Dans un scénario de migration, acté sur cinq années de transition, l’étude montre que l’analyse de portabilité vers PostgreSQL est la principale dépense au cours de la première année, suivie par un investissement important pour la recherche et le développement d’un socle d’outils dédiés aux déploiements, la maintenance et l’administration du parc PostgreSQL.
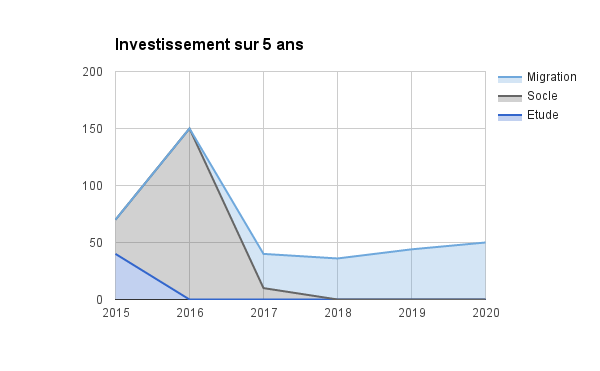
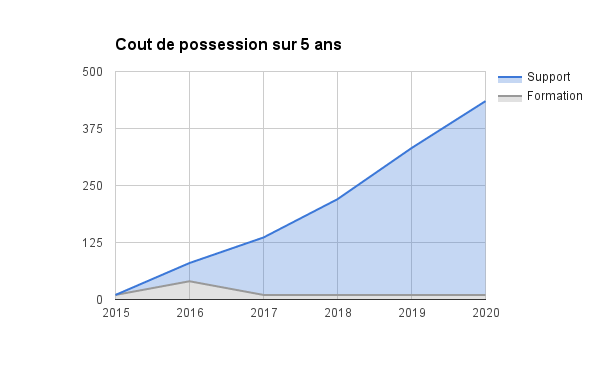
La seconde courbe peut paraître surprenante pour du logiciel libre, mais la nécessité de contracter une offre de support reste d’actualité, car trop peu de services informatiques disposent des compétences internes pour assurer la disponibilité et la maintenance des instances. Un effort initial de formation est requis pour aider les administrateurs en poste à faire également leur transition vers cette autre technologie.
Pour cette raison, de nombreux acteurs se positionnent depuis des décennies pour proposer de l’accompagnement opérationnel et technique auprès des entreprises de toutes tailles qui souhaitent (principalement) réduire les coûts de licence de logiciels propriétaires. Et bien que la transition pouvait être pénible il y a dix ans, les dernières versions de PostgreSQL et la prolifération d’outils communautaires apportent leur lot de fonctionnalités qui ne rougissent plus devant les atouts phares de certains mastodontes historiques du marché.
S’armer d’outils et de courage
Réaliser une migration impose de s’équiper d’un panel d’outils pour simplifier les grandes lignes de la migration et bien sûr, économiser du temps et de l’argent. Parmi les contributions libres, nous retrouverons l’incontournable Ora2pg, spécialisé dans la conversion d’un schéma Oracle et la migration de son contenu vers une instance PostgreSQL. Pour une base de type SQL Server de Microsoft, pgloader sera privilégié. Les deux outils supportent également les données en provenance de MySQL.
En juillet dernier, je partageais mes réflexions sur l’implémentation de la
norme SQL/MED et des foreign data wrappers, ou connecteurs. L’actualité fut
particulièrement riche cet été, avec la sortie de la version 22.0 du projet
Ora2Pg, dont le nouveau support de l’extension oracle_fdw annonçait des gains
vertigineux sur le temps de copie des données.
Ni une ni deux, j’ai souhaité comprendre et découvrir les dessous d’un tel procédé en manipulant moi-même les tables externes pour réaliser une migration de schémas et de données d’une base Oracle vers PostgreSQL, sans utiliser l’outil Ora2Pg. Cette procédure s’inspire d’un autre article de MigOps, publié plus tôt cette année.
1. Compiler le wrapper communautaire
Le connecteur oracle_fdw nécessite d’être compilé à partir des sources du projet
pour prendre en compte les bibliothèques propriétaires d’Oracle, garantes du
protocole de connexion et des échanges de données. Dans l’exemple ci-dessous, je
dispose d’un serveur CentOS 7 avec une instance PostgreSQL 14 et j’ai installé
l’Instant Client 19, disponible sur la plateforme de téléchargement d’Oracle.
yum install -y postgresql14-devel
export ORACLE_HOME=/usr/lib/oracle/19.13/client64
export LD_LIBRARY_PATH=$ORACLE_HOME/lib
export PATH=$PATH:$ORACLE_HOME/bin
cd ORACLE_FDW_2_4_0/
make PG_CONFIG=/usr/pgsql-14/bin/pg_config
make PG_CONFIG=/usr/pgsql-14/bin/pg_config install
Pour résoudre d’éventuels problèmes de détection de la librairie Oracle
Instant Client et permettre la création de l’extension, il est nécessaire de
renseigner la variable $LD_LIBRARY_PATH pour l’instance PostgreSQL au niveau
de son service :
systemctl edit postgresql-14
[Service]
Environment="ORACLE_HOME=/usr/lib/oracle/19.13/client64"
Environment="LD_LIBRARY_PATH=/usr/lib/oracle/19.13/client64/lib"
L’extension peut ainsi être créée avec les privilèges d’un super-utilisateur
dans la base qui accueillera les données finales. Le privilège USAGE peut ensuite
être octroyé au propriétaire de la base pour préparer le schéma.
CREATE EXTENSION oracle_fdw;
GRANT USAGE ON FOREIGN DATA WRAPPER oracle_fdw TO hr;
2. Importer les tables externes
L’unique configuration repose sur la création d’un objet SERVER et l’attribution
d’un mot de passe pour l’utilisateur courant, afin d’ouvrir un pont entre les
deux systèmes.
CREATE SERVER orcl_hr FOREIGN DATA WRAPPER oracle_fdw
OPTIONS (dbserver '//localhost:1521/hr');
CREATE USER MAPPING FOR hr SERVER orcl_hr
OPTIONS (user 'hr', password 'demo');
La magie du wrapper opère lors de l’inspection de la base de données externe et de la création des relations dans un schéma PostgreSQL. Dans mon exemple, je dispose d’une base Oracle XE avec le schéma prédéfini HR contenant une variété de tables, de vues, d’index et de contraintes d’intégrité.
CREATE SCHEMA source;
SET search_path = source;
IMPORT FOREIGN SCHEMA "HR" FROM SERVER orcl_hr INTO source;
Avec psql et la méta-commande \dE, il est dès lors possible de consulter les
tables externes importées dans le schéma source. L’une des huit tables est en
réalité une vue, car l’extension consulte le catalogue ALL_TAB_COLUMNS dans
lequel figurent les tables et vues accessibles par l’utilisateur connecté. Dans
la phase d’étude de la migration, ce point doit être correctement identifié pour
récupérer l’ordre de création de la vue, en adaptant la requête SQL si besoin.
List of relations
Schema | Name | Type | Owner
--------+------------------+---------------+-------
source | countries | foreign table | hr
source | departments | foreign table | hr
source | emp_details_view | foreign table | hr
source | employees | foreign table | hr
source | job_history | foreign table | hr
source | jobs | foreign table | hr
source | locations | foreign table | hr
source | regions | foreign table | hr
3. Créer les tables et les vues
Pour chacune de ces tables externes, il faut créer leur équivalent dans la base
PostgreSQL. Pour mon exemple, je choisis le schéma public comme destination.
L’une des méthodes les plus rapides repose sur l’option LIKE de l’instruction
CREATE TABLE.
CREATE TABLE public.countries (LIKE source.countries);
CREATE TABLE public.departments (LIKE source.departments);
CREATE TABLE public.employees (LIKE source.employees);
CREATE TABLE public.job_history (LIKE source.job_history);
CREATE TABLE public.jobs (LIKE source.jobs);
CREATE TABLE public.locations (LIKE source.locations);
CREATE TABLE public.regions (LIKE source.regions);
À partir de cette étape, il est judicieux d’apporter quelques modifications aux
types de colonnes. En effet, les types DATE et NUMBER en provenance d’Oracle
ont des équivalences bien plus riches et efficientes avec PostgreSQL. Pour aller
plus loin, l’un des chapitres de la formation Dalibo « Migrer d’Oracle à
PostgreSQL » revient sur les différences notables entre les deux systèmes.
ALTER TABLE public.regions ALTER region_id TYPE smallint;
ALTER TABLE public.countries ALTER region_id TYPE smallint;
ALTER TABLE public.employees ALTER hire_date TYPE date;
ALTER TABLE public.job_history
ALTER start_date TYPE date,
ALTER end_date TYPE date;
La vue, quant à elle, doit être recréée pour les besoins de l’application.
CREATE OR REPLACE VIEW public.emp_details_view (
employee_id, job_id, manager_id, department_id, location_id, country_id,
first_name, last_name, salary, commission_pct, department_name, job_title,
city, state_province, country_name, region_name
) AS
SELECT e.employee_id, e.job_id, e.manager_id, e.department_id, d.location_id,
l.country_id, e.first_name, e.last_name, e.salary, e.commission_pct,
d.department_name, j.job_title, l.city, l.state_province,
c.country_name, r.region_name
FROM public.employees e
JOIN public.departments d ON e.department_id = d.department_id
JOIN public.jobs j ON j.job_id = e.job_id
JOIN public.locations l ON d.location_id = l.location_id
JOIN public.countries c ON l.country_id = c.country_id
JOIN public.regions r ON c.region_id = r.region_id;
4. Importer les données
La méthode la plus simple pour importer les données reste la copie table à table
avec l’instruction INSERT INTO. Avec PostgreSQL, la commande TABLE est
équivalente à un SELECT * FROM, que j’utilise pour alléger les requêtes dans
l’exemple ci-dessous.
INSERT INTO public.countries TABLE source.countries;
INSERT INTO public.departments TABLE source.departments;
INSERT INTO public.employees TABLE source.employees;
INSERT INTO public.job_history TABLE source.job_history;
INSERT INTO public.jobs TABLE source.jobs;
INSERT INTO public.locations TABLE source.locations;
INSERT INTO public.regions TABLE source.regions;
Dans le cas de tables hautement volumineuses, cette méthode montrera très vite des faiblesses de performance, car les instructions sont exécutées les unes après les autres et que le parcours d’une table distante n’est réalisé que par un seul processus.
À moins de développer son propre système de distribution de requêtes et de lectures parallélisées, sachez que l’outil Ora2Pg propose parfaitement des pistes d’optimisation pour accélérer grandement les insertions lors de cette phase de chargement.
5. Créer les séquences, les index et les contraintes
Cette dernière étape est indispensable pour maintenir la cohérence du modèle et pour garantir des performances similaires, il ne faut donc pas mésestimer la phase d’étude qui permettra d’inventorier les séquences, les index et les contraintes à recréer dans la base PostgreSQL. Pour aller jusqu’au bout de ma démonstration, voici les instructions à exécuter pour finaliser la migration.
-- regions
ALTER TABLE regions
ADD CONSTRAINT reg_id_pk PRIMARY KEY (region_id);
-- countries
ALTER TABLE countries
ADD CONSTRAINT country_c_id_pk PRIMARY KEY (country_id),
ADD CONSTRAINT countr_reg_fk FOREIGN KEY (region_id)
REFERENCES regions(region_id);
-- locations
CREATE SEQUENCE locations_seq
START WITH 3300 INCREMENT BY 100 MAXVALUE 9900;
ALTER TABLE locations
ALTER location_id SET DEFAULT nextval('locations_seq'::regclass),
ADD CONSTRAINT loc_id_pk PRIMARY KEY (location_id),
ADD CONSTRAINT loc_c_id_fk FOREIGN KEY (country_id)
REFERENCES countries(country_id);
-- departments
CREATE SEQUENCE departments_seq
START WITH 280 INCREMENT BY 10 MAXVALUE 9990;
ALTER TABLE departments
ALTER department_id SET DEFAULT nextval('departments_seq'::regclass),
ADD CONSTRAINT dept_id_pk PRIMARY KEY (department_id),
ADD CONSTRAINT dept_loc_fk FOREIGN KEY (location_id)
REFERENCES locations (location_id);
-- jobs
ALTER TABLE jobs
ADD CONSTRAINT job_id_pk PRIMARY KEY(job_id);
-- employees
CREATE SEQUENCE employees_seq
START WITH 207 INCREMENT BY 1;
ALTER TABLE employees
ALTER employee_id SET DEFAULT nextval('employees_seq'::regclass),
ADD CONSTRAINT emp_emp_id_pk PRIMARY KEY (employee_id),
ADD CONSTRAINT emp_dept_fk FOREIGN KEY (department_id)
REFERENCES departments,
ADD CONSTRAINT emp_job_fk FOREIGN KEY (job_id)
REFERENCES jobs (job_id),
ADD CONSTRAINT emp_manager_fk FOREIGN KEY (manager_id)
REFERENCES employees;
ALTER TABLE departments
ADD CONSTRAINT dept_mgr_fk FOREIGN KEY (manager_id)
REFERENCES employees (employee_id);
-- job_history
ALTER TABLE job_history
ADD CONSTRAINT jhist_emp_id_st_date_pk PRIMARY KEY (employee_id, start_date),
ADD CONSTRAINT jhist_job_fk FOREIGN KEY (job_id)
REFERENCES jobs,
ADD CONSTRAINT jhist_emp_fk FOREIGN KEY (employee_id)
REFERENCES employees,
ADD CONSTRAINT jhist_dept_fk FOREIGN KEY (department_id)
REFERENCES departments;
Dans des situations particulièrement simples, la migration vers PostgreSQL peut être intégralement réalisée à l’aide du langage SQL et d’une extension de la famille des foreign data wrappers. Cependant, le temps de copie restera très dépendant de l’ordonnancement que l’on peut en faire, et du débit de transfert entre les deux systèmes.
Conclusion
La migration deviendra complexe lorsque la base de données à migrer embarque du code PL/SQL stratégique. À moins d’extraire la logique métier et de l’implémenter dans une application dédiée, la conversion du code en routines PL/pgSQL méritera toute votre attention. Bien qu’Ora2Pg puisse simplifier le travail de portage avec une conversion automatique tout à fait honorable, il sera indispensable de tester la non-régression fonctionnelle.
Un outil comme pgTAP peut aider à rédiger des tests unitaires ou de bout en bout pour couvrir le code et vous accompagner dans le portage des procédures. L’année dernière, j’avais pris plaisir à rédiger un atelier complet sur la traduction des procédures PL/SQL fournies avec le schéma HR présenté aujourd’hui. N’hésitez pas à le consulter !