Dessine-moi un arbre (abstrait)
- 6 minutes de lecture
L’étape d’analyse crée un arbre d’analyse qui n’utilise que les règles fixes de la structure syntaxique de SQL. Il ne fait aucune recherche dans les catalogues système. Il n’y a donc aucune possibilité de comprendre la sémantique détaillée des opérations demandées.
(Documentation : Processus de transformation)
Que se passe-t-il entre l’instant où une requête SQL est soumise par l’utilisateur et l’envoi du résultat sous forme de lignes par le serveur PostgreSQL ? Cette question passionnante (pour une poignée de personnes, ne nous le cachons pas) a été étudiée par Stefan Simkovics durant sa thèse pour l’université de technologie de Vienne en 1998.
Ces travaux ont notamment permis d’enrichir la documentation officielle avec le chapitre « Présentation des mécanismes internes de PostgreSQL », qui reprend assez largement les observations de Simkovics de manière simplifiée pour en faciliter l’accès au plus grand nombre.
Dans cet article, je souhaite présenter de récentes découvertes sur l’une de ces phases internes, l’étape d’analyse, qui permet de manipuler une requête SQL sous une forme d’arbre et qui respecte un pattern de développement avancé nommé AST (abstract syntax tree).
Du code à la machine
Exprimer une instruction sous forme de mots comme le propose le langage SQL implique que le moteur responsable du traitement de ladite instruction soit capable de l’interpréter. Une analogie très simple peut être faite avec le langage commun, où des règles de grammaire fixent l’ordre des adjectifs, noms et pronoms pour que deux interlocuteurs puissent s’exprimer et se comprendre.
En informatique, ce processus s’appelle la compilation et fait le lien entre les instructions du code source et leurs opérations équivalentes soumise à la machine qui exécutera le code compilé. Depuis l’aube du numérique, une poignée de logiciels est chargée d’analyser les instructions, que l’on pourra distinguer en plusieurs familles :
- L’analyse lexicale prend en charge la détection des mots-clés ou lexème, ainsi que les espacements ou les blocs de commentaires. Les analyseurs lexicaux (scanners) les plus connus sont Lex et Flex (la version GNU de Lex) ;
- L’analyse syntaxique énonce les règles qui permet de rattacher les lexèmes avec des relations de dépendances, que l’on nomme syntagmes, afin d’en sortir une représentation de l’instruction sous forme d’arbre d’analyse. Les analyseurs syntaxiques (parsers) sont fréquemment Yacc et Bison (la version GNU de Yacc) ;
- L’analyse sémantique s’assure que les éléments définis par les étapes précédentes soient suffisamment complets et contrôle le bon usage des lexèmes dans leur contexte (déclaration de variable, correspondance de type lors d’une affectation, etc.)
Cet enchainement d’étapes est scrupuleusement implémenté dans PostgreSQL lorsqu’il s’agit d’interpréter une requête SQL soumise par un utilisateur. Le rapport de thèse de Simkovics prend en exemple la requête suivante :
SELECT s.sname, se.pno
FROM supplier s, sells se
WHERE s.sno > 2 AND s.sno = se.sno;
L’étape d’analyse (ou parsing) va donc découper chaque mot de l’instruction et
les regrouper en lexèmes (mots-clé du langage, identifiants, opérateurs,
littéraux). Dès qu’une erreur de syntaxe est rencontrée, comme une virgule juste
avant le mot-clé FROM, le traitement de la requête est interrompu et un message
d’erreur explicite est retourné à l’utilisateur :
ERROR: syntax error at or near "FROM"
LINE 2: FROM supplier s, sells se
Dans le cas où la requête est syntaxiquement correcte, l’arbre d’analyse est
consolidé en mémoire pour lier les lexèmes selon les règles de grammaire du
langage. Ainsi, les tables de la clause FROM sont rattachées en tant que nœuds
RangeVar à l’attribut fromClause du nœud principal SelectStmt. Il en va de
même pour la représentation des colonnes et de la clause WHERE de la requête
à travers les nœuds targetList et whereClause respectivement.
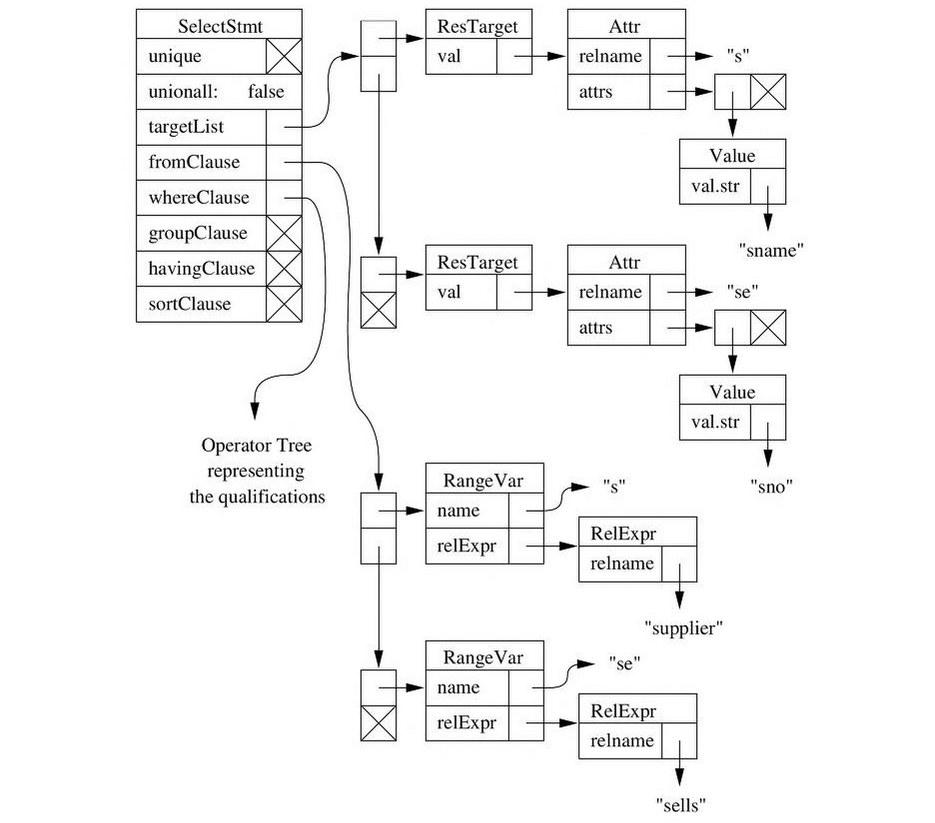
Cet arbre est ensuite transformé par une nouvelle étape de réécriture, chargée de réaliser des optimisations entre les nœuds et retirer les branches superflues. Entrent alors en scène deux autres mécanismes, à savoir l’optimiseur (planner) et l’exécuteur (executor), que je n’aborderais pas dans cet article, qui consommeront l’arbre ainsi finalisé pour construire le résultat de données à transmettre à l’utilisateur.
Reconstruire un arbre abstrait
J’ai récemment écrit des requêtes SQL dynamiques dans le cadre d’un projet PL/pgSQL. Cette pratique est assez courante, il s’agit d’accoler plusieurs bouts d’expressions pour écrire une requête SQL dont les parties (colonnes, tables, conditions) peuvent varier. Voici en substance, le prototype de ce code :
DO $prototype$
DECLARE
r record;
v_columns text;
v_tabname text;
v_values text := $$ 1, 'test' $$;
BEGIN
SELECT value INTO v_tabname
FROM config WHERE name = 'table_name';
SELECT string_agg(value, ',') INTO v_columns
FROM config WHERE name = 'column_name';
EXECUTE format(
'INSERT INTO %s (%s) VALUES (%s);',
v_tabname, v_columns, v_values
);
END;
$prototype$;
Ici, le contenu de la table config est déterminant pour que ce code construise
une requête INSERT syntaxiquement correcte. De plus, dans l’éventualité plus que
probable où la fonctionnalité ait besoin de s’enrichir, ledit code se complexifie
et rencontrera très certainement des difficultés de maintenance et d’évolution.
Parlant à l’un de mes collègues des complications évidentes que j’allais rencontrer dans mon développement, ce dernier m’oriente vers un pattern plus avancé pour rendre le code plus modulable à l’aide d’une abstraction supplémentaire, le susnommé AST. Cette méthode repose intégralement sur la représentation en arbre d’un objet complexe qu’il devient possible de manipuler et de modeler librement.
Dans le cas de mon exemple, il s’agissait de :
- Construire la requête SQL sous la forme d’un arbre syntaxique ;
- Rendre à la requête sa forme textuelle pour l’exécuter sans faute lexicale ni syntaxique.
Dans les semaines qui suivirent, la solution se présenta à moi avec l’extension postgres-ast-deparser, dédiée à la construction d’arbres abstraits et la réécriture au format SQL de la requête (deparsing). Après quelques échanges avec son auteur Dan Lynch, je me suis servi d’une série de fonctions pour améliorer mon prototype.
DO $prototype$
DECLARE
v_relation jsonb;
v_columns jsonb;
v_values jsonb := to_jsonb(ARRAY[ARRAY[
ast.a_const(v_val := ast.integer(1)),
ast.a_const(v_val := ast.string('test'))
]]);
BEGIN
SELECT ast_helpers.range_var(
v_schemaname := 'public',
v_relname := value) INTO v_relation
FROM config WHERE name = 'table_name';
SELECT jsonb_agg(ast.res_target(
v_name := value)) INTO v_columns
FROM config WHERE name = 'column_name';
EXECUTE deparser.expression(ast.insert_stmt(
v_relation := v_relation,
v_cols := v_columns,
v_selectStmt := ast.select_stmt(
v_valuesLists := v_values,
v_op := 'SETOP_NONE'
)
)) FROM config WHERE name = 'table_name';
END;
$prototype$;
L’extension propose une série de méthodes dans les schémas ast et ast_helpers
pour obtenir les nœuds de l’arbre sous forme de JSONB. L’imbrication de plusieurs
appels permet de reconstruire l’arbre dans sa totalité pour finalement obtenir la
structure InsertStmt telle que définie par l’analyseur syntaxique de PostgreSQL
lui-même !
Conclusion
En manipulant des arbres sous forme de JSONB, j’ai perçu l’intérêt que peuvent
avoir des projets comme postgres-ast-deparser. Ce dernier repose d’ailleurs
sur les travaux de la société qui édite pganalyze en
proposant ni plus ni moins d’utiliser le parser interne de PostgreSQL à l’extérieur
de ce dernier à l’aide de la librairie libpg_query !
Les cas d’usage sont nombreux, tels que la colorisation ou la validation syntaxique,
reformater les sauts de lignes d’une requête, sérialiser la requête pour modifier
une partie de ses nœuds, etc. La documentation de pglast (un autre parser
pour Python) propose d’autres exemples d’utilisation si d’aventure, cet article
a éveillé votre curiosité.