Les modes de transfert dans une migration
- 8 minutes de lecture
En informatique, un projet de migration consiste à changer un ou plusieurs composants techniques sans qu’aucun comportement des applications n’en soit impacté. Dans le paysage des bases de données (et le métier que j’exerce), il s’agira de choisir un nouveau système (comme PostgreSQL) en remplacement d’un autre (comme Oracle ou Microsoft SQL Server).
Dans un précédent article, je décrivais les étapes exhaustives pour réaliser une migration complète à l’aide de la technologie des Foreign Data Wrappers, mais l’étape critique de transfert des données qui y était décrite ne s’adapte pas à toutes les situations. Voyons ensemble les alternatives qui permettent de couvrir une grande partie des besoins.
Transfert sans réseau
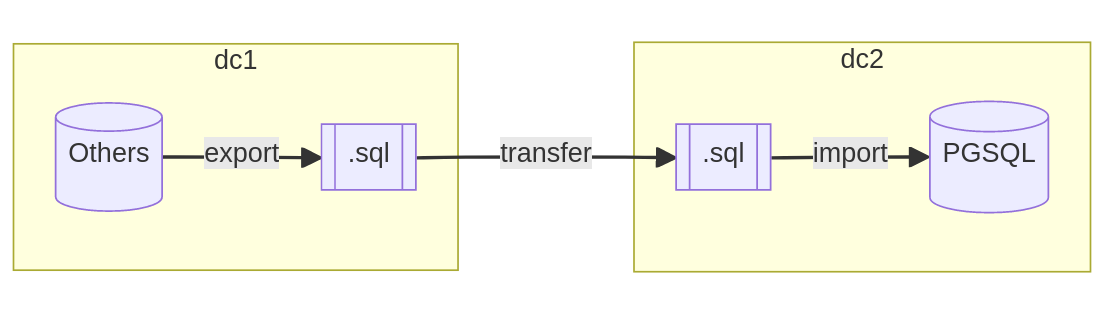
Plusieurs raisons peuvent justifier que les deux serveurs ne soient pas en connexion directe de l’un à l’autre. Comme l’interdiction d’ouvrir l’accès à l’instance source depuis Internet ou la complexité de configurer un lien sécurisé (VPN) entre les deux infrastructures.
Dans ce genre de scénario, il devient nécessaire de déverser les données en dehors de la base en garantissant la cohérence de ces dernières. Une sauvegarde physique de la base ou un export au format SQL sont des moyens fiables pour consolider une archive complète de la base.
L’étape de transfert est opérée selon l’imagination des équipes. Le plus simple reste le transfert sur un dépôt SFTP mis à disposition par le deuxième datacenter ou tout autre protocole qui contrôle l’intégrité de l’archive une fois transférée. La méthode la plus improbable que j’ai pu observer, était le déplacement physique d’une copie de l’archive par une société spécialisée de coursiers, en voiture, en scooter, ou en avion selon la distance à parcourir.
Une fois l’archive réceptionnée par les équipes et jugée intègre, il peut être nécessaire d’importer les données dans une base tampon, pour peu que le format de fichiers (SQL ou propriétaire) ne soit pas encore compatible avec PostgreSQL. Dès ce moment précis, il est alors possible d’importer les données dans la base cible en respectant l’ordre de créations des objets et l’insertion des données.
Bilan de l’opération :
- Temps d’interruption très élevé (de plusieurs heures à plusieurs jours) ;
- Complexité de mise en œuvre faible avec les bons outils ;
- Risque sur la cohérence des données très faible si les contrôles d’intégrité sont réalisés à chaque étape.
Transfert avec intermédiaire
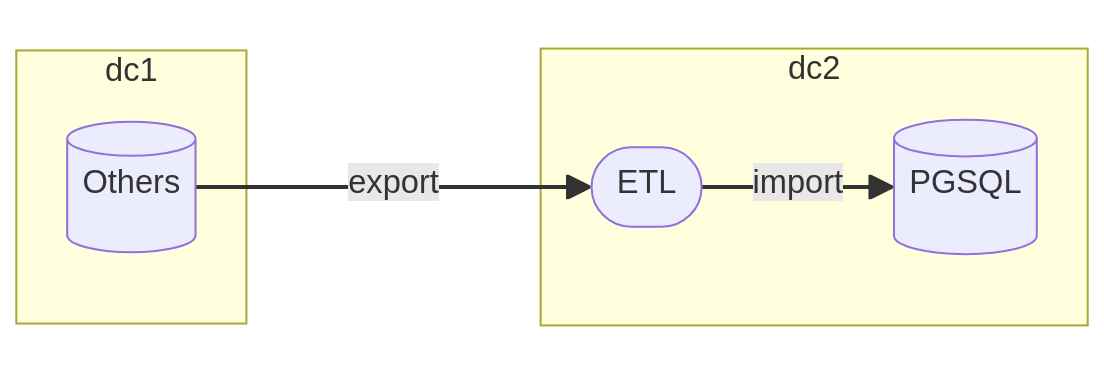
Lorsque les systèmes sont hébergés au même endroit, la mise en place de règle de routage permet plus aisément de rendre possible la connexion entre les deux serveurs. Parmi les outils de migration, on retrouve la famille des ETL (pour Extract Transform Load) qui font office d’intermédiaire entre les deux bases de données.
Ces outils fournissent une grande quantité de pilotes de connexion ainsi que des méthodes de transformation de la donnée pour orchestrer la migration sans avoir besoin d’exporter la moindre table dans un fichier plat. L’essentiel du travail est donc réalisé en mémoire et à l’aide de plusieurs processeurs pour accélérer les opérations de transfert.
Bien que spécialisé pour les migrations vers PostgreSQL, je range l’outil libre
Ora2Pg dans la catégorie des ETL. Il répond exactement à la définition
précédente en ouvrant plusieurs connexions sur l’instance source pour lire les
table par paquet de 10 000 lignes (directive DATA_LIMIT) et en ouvrant
d’autres connexions sur l’instance cible pour les insérer avec des instructions
COPY, grâce à la méthode pg_putcopydata du pilote DBD::Pg.
Bilan de l’opération :
- Temps d’interruption élevé (plusieurs heures) ;
- Complexité de mise en œuvre faible avec les bons outils ;
- Risque sur la cohérence des données très faible.
Transfert en direct
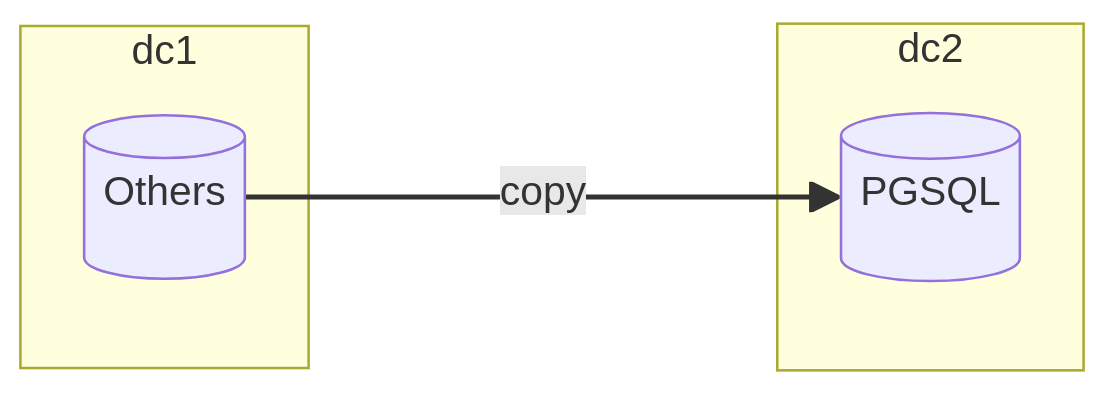
Ce mode devrait vous paraître familier si vous êtes des habitué·es de mes articles (abonnez-vous) car le transfert direct entre un système tiers et PostgreSQL repose sur la technologie des Foreign Data Wrappers.
Cette solution permet d’ouvrir un canal direct entre l’instance PostgreSQL et l’instance distante par le biais de tables externes. Ainsi, il devient possible de consulter les données avec le langage SQL, pour peu qu’un wrapper ait été développé pour communiquer avec le bon pilote.
Les opérations d’extraction, de transfert et d’insertion sont réalisées dans la
même transaction : il s’agit d’une bête requête INSERT INTO SELECT. Cette
méthode est bien plus rapide que le mode précédent puisque l’on se
débarrasse d’un intermédiaire coûteux en ressources (ETL).
Bien que séduisante, la copie par wrapper peut être particulièrement lente pour les données larges (comme les BLOB d’Oracle) car celles-ci ont une structure différente. Il est alors nécessaire de mixer les solutions : l’une avec un transfert direct pour les tables sans données larges, et l’autre avec un ETL pour optimiser plus finement le volume de lignes et la quantité de mémoire à allouer.
Bilan de l’opération :
- Temps d’interruption élevé (de plusieurs minutes à plusieurs heures) ;
- Complexité de mise en œuvre faible voire élevée pour les données larges ;
- Risque sur la cohérence des données très faible.
Transfert avec rattrapage partiel
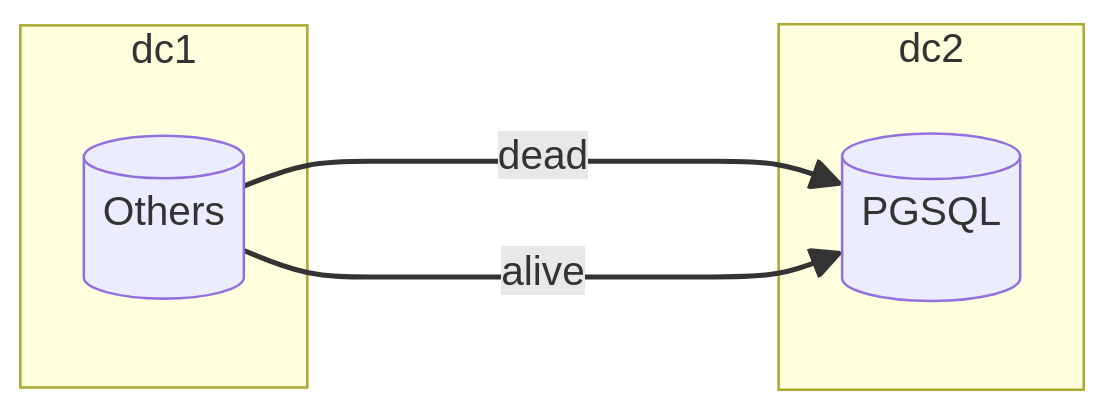
Pour de très hautes volumétries où l’interruption de service doit être la plus faible possible, les solutions citées plus haut peuvent être très limitantes. En effet, exporter/importer la totalité des données est une étape longue et incontournable.
Ce que j’appelle le transfert avec « rattrapage partiel » consiste à identifier
les tables les plus volumineuses dont la plupart des lignes sont mortes. Il faut
avoir l’assurance qu’aucune modification de type UPDATE ou DELETE n’ait lieu
auprès de l’équipe de développement et que la table présente une clé primaire
dont les nouvelles valeurs lors d’une insertion sont toujours supérieures à la
précédente.
Ainsi, une première copie des données peut être réalisée à chaud, sans interruption de service où seules les lignes mortes seront déplacées vers le nouveau système. Selon la proportion sur le volume complet, cette étape peut faire économiser des dizaines d’heures à l’opération finale. En complément des opérations de transfert, il est nécessaire de maintenir un registre des valeurs de clé primaire qui permet de séparer les données mortes des données vivantes (ou à venir). Pour chaque table, cette valeur sera une sorte de point de reprise pour la phase de rattrapage.
Lors de l’étape cruciale de bascule, toutes les tables vivantes seront intégralement copiées et les lignes des tables mortes dont la clé est supérieure à la valeur mémorisée seront sélectionnées puis insérées dans leur table respective. Une étude préalable doit déterminer si les index méritent d’être créés lors de la première ou de la seconde étape de transfert, en fonction du temps effectif qu’ils font perdre ou gagner sur l’opération dans sa globalité.
Bilan de l’opération :
- Temps d’interruption faible (plusieurs dizaines de minutes) ;
- Complexité de mise en œuvre élevée ;
- Risque sur la cohérence des données élevé si l’équipe de développement n’apporte pas toutes les garanties suffisantes dans le choix des tables mortes.
Transfert avec rejeu des transactions
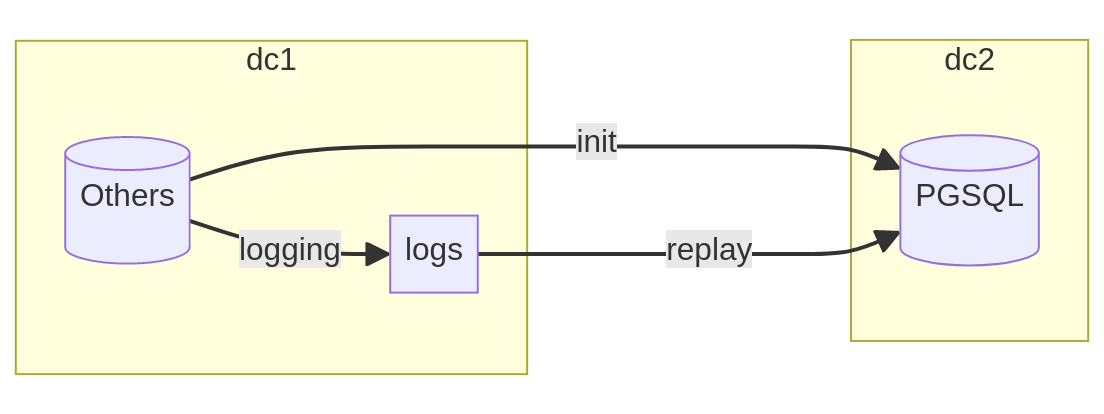
Parler de « rejeu des transactions » revient très sobrement à parler de réplication physique ou de réplication logique. Chaque système propose des mécanismes qui lui sont propres et les outils à mettre en place peuvent donc varier. Je vous invite à vous pencher sur de brillants projets comme ora_migrator qui implémente une réplication par triggers avec Oracle et pg_chameleon qui décode les journaux de transactions de MySQL.
L’intérêt principal de ce mode de transfert repose sur la capacité du système à journaliser (logging) toutes les modifications qui lui ont été demandées et de les renseigner dans une succession de transactions. Ainsi, entre un instant T0 et un instant T1, il devient possible de reproduire l’ensemble des changements pour atteindre un état cohérent et fidèle.
Dans ce scénario, l’opération requiert un chargement intégral et cohérent des données dans la base cible. Cette phase d’initialisation se réalise sans interruption de service mais nécessite un soin particulier dans la supervision des disques ou les alertes du système source, car la capture des données provoque le maintien d’un instantané (snapshot) qui peut devenir coûteux si le transfert s’éternise.
À l’issue de l’initialisation, le rejeu peut démarrer à chaud sans pénaliser
l’activité de la base source de production. L’outil consomme chaque événement
dans l’ordre d’arrivée pour le transformer en écriture (INSERT, UPDATE ou
DELETE) dans la base PostgreSQL. L’opération de bascule consiste alors à
interdire toute nouvelle modification sur le système source, attendre la fin du
rejeu et changer les chaînes de connexions pour que les applications se
connectent sur la nouvelle base PostgreSQL.
Bilan de l’opération :
- Temps d’interruption très faible (quelques secondes) ;
- Complexité de mise en œuvre élevée voire très élevée selon les solutions retenues ;
- Risque sur la cohérence des données très élevé si l’outil tombe en erreur pour une transaction qu’il ne parvient pas à décoder lors de l’étape de rejeu.
Le choix est libre
Cette revue complète et exhaustive me hantait depuis quelque temps, et il me semblait nécessaire de mettre en lumière les différentes contraintes que présente un projet de migration. Dans la sphère des consultants que je fréquente et des projets libres que je surveille activement, j’essaie de me convaincre qu’il peut exister une solution universelle, capable d’adresser chaque besoin et situation qui ont été dépeints dans cet article.
J’ai délibérément évité de parler du projet Debezium, car il repose sur de nombreuses briques techniques comme Kafka, Java et une myriade de connecteurs. Et bien qu’une conférence à ce sujet m’ait tenu en haleine en juin dernier, je n’ai pas encore eu l’occasion de mener un projet d’envergure qui justifiait un tel investissement humain dans sa mise en œuvre.
Les outils libres ou payants sont nombreux, tous n’ont pas la même vocation ni la même philosophie. Privilégier l’un plutôt qu’un autre revient aux équipes en charge de la migration et de leur maturité technique mais au final, le choix est libre !