Un assistant pour copier les données distantes
- 11 minutes de lecture
Lors de la dernière PGSession 16, j’ai rédigé et animé un atelier de
trois heures au sujet de la migration vers PostgreSQL à l’aide des Foreign Data
Wrappers, ou FDW. Ce fut notamment l’occasion de présenter au grand public,
l’extension db_migrator pour laquelle j’ai dédié un article sur ce
blog.
Au cours de cet atelier, nous pouvons constater que la copie des données avec
l’extension db_migrator n’est pas parfaitement prise en charge. En effet, bien
qu’il existe une fonction de bas niveau pour répartir sur plusieurs processus le
transfert table à table, de nombreuses situations devront exiger de rédiger un
grand nombre de requêtes SQL pour se tirer d’affaire. Au cours des mois qui
suivirent, je me suis attelé à la conception d’un assistant écrit en
PL/pgSQL dont le but est de simplifier la génération de ces requêtes.
Transfert des données sans assistant
Il n’y a pas de magie dans l’opération de copie des données à travers un Foreign
Data Wrapper. Tout se résume à une série de requêtes INSERT qui doivent être
exécutées dans un ordre prédéfini. Prenons les 16 tables du modèle de données
très connu « Sakila » (disponible à cette adresse), pour illustrer le
besoin de génération des requêtes de transfert.
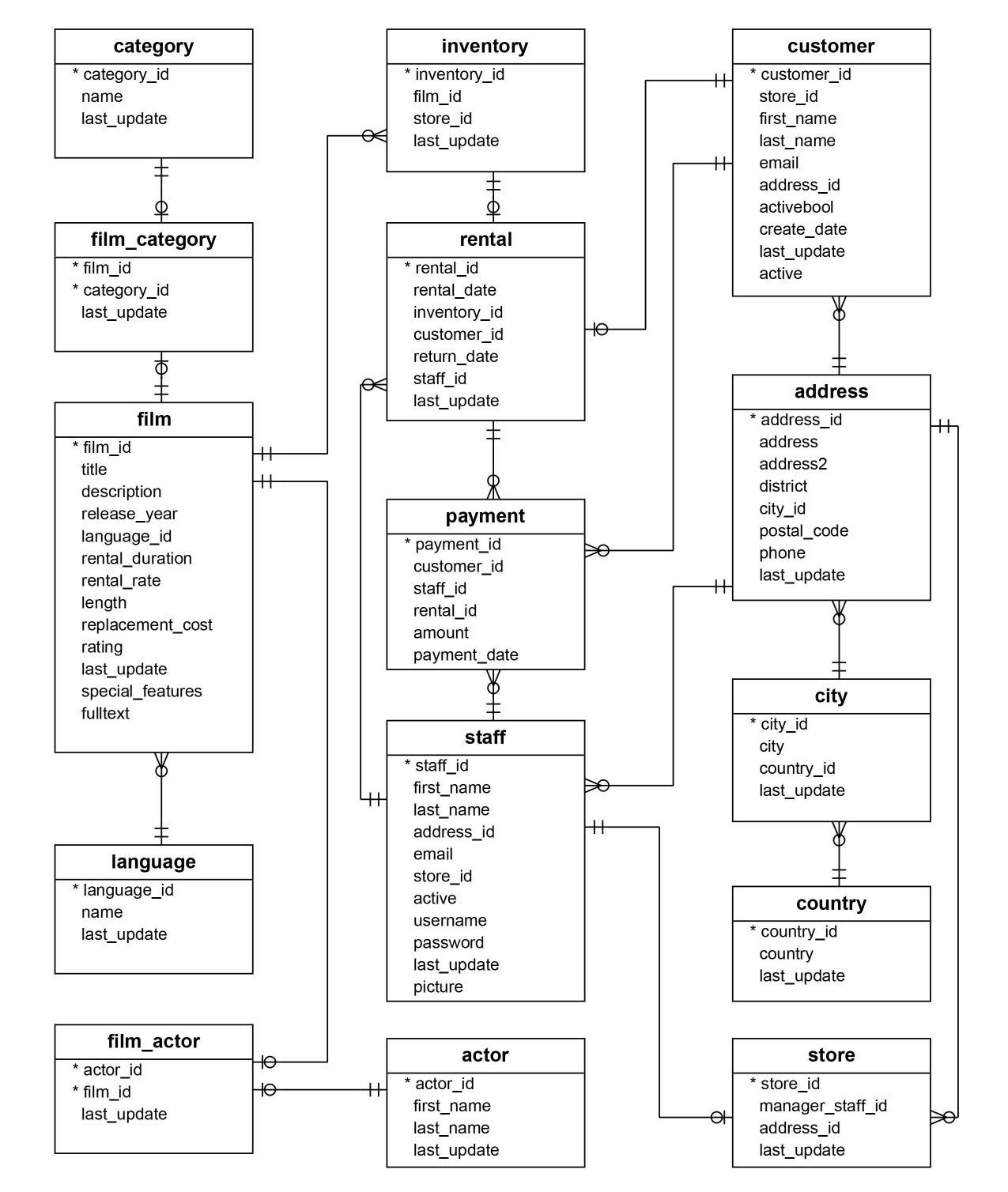
Pour la pédagogie de cet article, je dispose d’une base de données PostgreSQL avec les deux schémas suivants que j’utiliserai dans mes démonstrations :
mysql: le schéma source contenant la définition des tables externes via l’extensionmysql_fdw;public: le schéma cible où les données seront copiées.
Chaque table externe fait l’objet d’une étude rapide pour obtenir la bonne
correspondance de type de colonne, et leur définition est conservée dans un
fichier SQL à destination des équipes du projet. Par exemple, la table externe
rental est définie comme suit :
CREATE FOREIGN TABLE mysql.rental (
rental_id integer NOT NULL,
rental_date timestamp without time zone NOT NULL,
inventory_id integer NOT NULL,
customer_id smallint NOT NULL,
return_date timestamp without time zone,
staff_id smallint NOT NULL,
last_update timestamp without time zone NOT NULL
)
SERVER sakila_mysql
OPTIONS (
dbname 'sakila',
table_name 'rental'
);
Lors de la création de la table public.rental qui accueillera les données, il
est opportun de décider si nous souhaitons mettre en place un partitionnement,
chose que db_migrator est capable d’identifier et de mettre en place. Pour
l’exemple, je reprends la structure stricte à l’aide de la syntaxe CREATE TABLE LIKE pour créer toutes mes tables cibles.
CREATE TABLE public.actor (LIKE mysql.actor);
CREATE TABLE public.address (LIKE mysql.address);
...
Avant même de mettre en place un générateur de requêtes INSERT, il est aisé
d’entrevoir la forme de celles-ci. Chaque ligne de la table externe sera lue à
travers un SELECT global, puis insérée dans la table cible. Le script de
migration contient ainsi 16 instructions, une pour chaque table.
-- insert.sql
INSERT INTO public.actor SELECT * FROM mysql.actor;
INSERT INTO public.address SELECT * FROM mysql.address;
...
INSERT INTO public.store SELECT * FROM mysql.store;
Pour bénéficier de plusieurs processus, j’apprécie l’outil xargs qui permet de
distribuer chaque ligne du fichier insert.sql sur une nouvelle session psql.
Cette technique était présentée dans l’atelier de février, notamment pour
paralléliser la construction des index et des clés primaires, définis dans un
fichier SQL.
$ xargs -P 4 -a insert.sql -d '\n' -I % sh -c 'psql -c "%"'
INSERT 0 16
INSERT 0 603
...
INSERT 0 16044
C’est un peu rude, ça manque de verbosité, les requêtes SQL sont statiques. Bref, voyons la partie suivante pour découvrir ce que mon assistant peut apporter.
Démonstration de l’assistant
Contrairement à mes autres projets en PL/pgSQL, cet assistant n’est pas une extension et s’installe comme un vulgaire script. Une fois téléchargé, il suffit de l’invoquer sur la base de données de votre choix avec la commande suivante :
$ psql -d sakila -f fdw-assistant.sql
Le schéma par défaut se nomme assistant et contient une table de
configuration sobrement appelée config. Pour chaque table à migrer, il
suffit d’insérer une unique ligne qui servira d’élément de départ à la
génération des requêtes de migration des données. On y retrouve dans la version
actuelle les paramètres suivants :
source: la table externe qui contient les données à copier ;target: la table cible où les données seront copiées ;pkey: la colonne de clé primaire de la table cible ;priority: les valeurs les plus faibles définissent les tables à traiter en premier ;parts: le nombre de processus à lancer pour la copie des données ;trunc: une option pour vider la table cible avant de copier les données ;condition: une clauseWHEREpour filtrer les données à copier ;batchsize: le nombre de lignes à copier avant de réaliser unCOMMITintermédiaire.
Pour initialiser cette table en première intention, il est nécessaire de
connaître a minima les colonnes de clé primaire de chaque table distante. En
reportant les informations du diagramme relationnel de la base Sakila, nous
pouvons remplir la table config de la façon suivante :
INSERT INTO assistant.config (source, target, pkey)
VALUES
('mysql.actor', 'public.actor', 'actor_id'),
('mysql.address', 'public.address', 'address_id'),
...
('mysql.store', 'public.store', 'store_id');
Pour chaque transfert, nous indiquons la table source et la table cible, ainsi que la colonne de clé primaire. Cette dernière est requise pour trier les lignes, découper le transfert en plusieurs lots (batchs) et redémarrer le transfert en cas d’interruption.
À l’aide de cette configuration, nous pouvons passer à la planification. Les
tables stage et job sont alimentées avec de nouveaux éléments qui serviront
au pilotage et au suivi des différents transferts à déclencher.
SELECT * FROM assistant.plan();
target | invocation
---------------+--------------------------
customer | CALL assistant.copy(1);
address | CALL assistant.copy(2);
...
(16 rows)
Une vue nommée report permet de suivre l’avancement des différentes étapes
en joignant les tables stage et job. Elle donne notamment des éléments
très utiles pour suivre l’avancement et le débit des transferts.
SELECT target, state, rows FROM assistant.report WHERE stage_id = 1;
target | state | rows
---------------+---------+------
rental | pending | 0
actor | pending | 0
...
(16 rows)
Les lignes retournées par la commande plan() peuvent alors être invoquées
les unes après les autres avec la méta-commande \gexec de psql, ou alors en
reprenant la technique du fichier et la distribution des requêtes avec xargs.
L’appel à la méthode copy() se charge de construire l’instruction INSERT
relative à la copie des données d’une table distante vers une table locale. Par
exemple, pour la table customer, le résultat de l’appel sera le suivant :
CALL assistant.copy(1);
NOTICE: Executing: TRUNCATE public.customer
NOTICE: Executing: SELECT count(customer_id) FROM mysql.customer
WHERE customer_id > 0
NOTICE: Executing: INSERT INTO public.customer
SELECT customer_id, store_id, first_name, last_name, email,
address_id, active, create_date, last_update
FROM mysql.customer
WHERE customer_id > 0 ORDER BY customer_id
CALL
À l’issue du transfert, la vue report nous fait un résumé de l’opération.
SELECT * FROM assistant.report
WHERE stage_id = 1 AND target = 'public.customer'::regclass;
-[ RECORD 1 ]-------------------------
stage_id | 1
target | public.customer
job_start | 2024-05-28 10:19:18.334917
state | completed
rows | 599
total | 599
elapsed | 00:00:00.081273
rate | 7370.22
progress | 1.00
eti | 00:00:00
eta | 2024-05-28 10:19:18.334917
Distribution sur plusieurs processus
Au fur et à mesure de la conception de l’assistant, j’ai éprouvé le besoin
d’enrichir les requêtes sous-jacentes pour répondre à d’autres cas d’usage,
récurrents dans le domaine de la migration de données. Parmi ceux-ci, on y
retrouve la capacité de répartir les lignes d’une même table sur plusieurs
sessions, chacune disposant d’une clause WHERE basé sur le résultat de la
division euclidienne (modulo) de la clé primaire.
Pour activer cette fonctionnalité, il suffit de renseigner le paramètre parts
dans la table config. Par exemple, pour la table film, nous pouvons
définir :
UPDATE assistant.config SET parts = 4 WHERE target = 'public.film'::regclass;
Cette configuration prend effet lors de la prochaine planification. L’appel à la
méthode plan() insère alors quatre lignes dans la table job pour la table
film, chacune rattachée à une valeur comprise entre 0 et 3. La colonne
condition est alors enrichie pour les lignes de la table task en vue de
l’étape suivante.
SELECT invocation FROM assistant.plan('{public.film}');
invocation
--------------------------
CALL assistant.copy(17);
CALL assistant.copy(18);
CALL assistant.copy(19);
CALL assistant.copy(20);
(4 rows)
SELECT job_id, job.target, state, part, condition
FROM assistant.job JOIN assistant.task USING (job_id)
WHERE stage_id = 2;
job_id | target | state | part | condition
--------+--------+---------+------+-----------------
17 | film | pending | 0 | film_id % 4 = 0
18 | film | pending | 1 | film_id % 4 = 1
19 | film | pending | 2 | film_id % 4 = 2
20 | film | pending | 3 | film_id % 4 = 3
Lors de l’appel à la méthode copy(), l’assistant construit les requêtes
INSERT sur la base des conditions précédemment définies. Par exemple, pour la
première partie de la table film, la trace indique les requêtes INSERT qui
ont été générées.
CALL assistant.copy(17);
NOTICE: Executing: TRUNCATE public.film
NOTICE: Executing: SELECT count(film_id) FROM mysql.film
WHERE film_id > 0 AND film_id % 4 = 0
NOTICE: Executing: INSERT INTO public.film
SELECT film_id, title, description, release_year,
language_id, original_language_id, rental_duration,
rental_rate, length, replacement_cost, rating,
special_features, last_update
FROM mysql.film WHERE film_id > 0 AND film_id % 4 = 0
ORDER BY film_id
CALL
L’opération TRUNCATE intervient uniquement pour la session dont la valeur de
part est égale à 0. Dans le cas nominal, cette session est lancée avant toutes
les autres pour respecter le comportement attendu dans la configuration avec la
colonne trunc (true par défaut).
L’intérêt évident de cette méthode est d’obtenir le meilleur débit d’insertion
pour une table donnée, en reposant sur la puissance d’extraction du serveur
distant et la capacité d’écriture du serveur local. Le débit peut être consulté
avec la vue report, notamment pour comparer deux chargements pour une même
table, comme l’exemple de la table film. La colonne rate est exprimée en
nombre de lignes par seconde.
SELECT stage_id, target, state, rate FROM assistant.report
WHERE target = 'public.film'::regclass;
stage_id | target | state | rate
----------+-------------+-----------+----------
1 | public.film | completed | 19162.59
2 | public.film | completed | 51389.37
Reprise après interruption
La capacité de pouvoir relancer une copie par lot en cas d’interruption est une
des raisons pour lesquelles la clé primaire doit être renseignée dans la
configuration. L’assistant s’appuie sur la dernière valeur de clé primaire
extraite (à l’aide d’une clause RETURNING) pour connaître le prochain point de
reprise. Dans la conception de cette fonctionnalité, il m’a fallu arbitrer sur
les limitations qu’impose ce mécanisme.
- Les clés primaires ne doivent pas être composées, car la clause
RETURNINGne peut retourner qu’une seule valeur ; - Les tables dont la clé primaire est composée ne peuvent pas bénéficier du traitement par lot, et donc de la reprise après interruption ;
- Les données sont systématiquement triées lors de l’extraction, même si le traitement par lot n’est pas activé ;
- La colonne de la clé primaire doit être de type numérique.
L’activation d’un traitement par lot consiste à mettre à jour la colonne
batchsize de la table de configuration. Prenons l’exemple de la table
rental :
UPDATE assistant.config SET batchsize = 1000
WHERE target = 'public.rental'::regclass;
SELECT invocation FROM assistant.plan('{public.rental}');
invocation
--------------------------
CALL assistant.copy(21);
(1 row)
Le transfert des données de la table rental est alors découpé en lots de 1000
lignes. Il est bien sûr possible de combiner cette technique avec la
parallélisation, la clause WHERE réalisera l’essentiel du travail de
répartition pour empêcher que la même ligne soit exportée deux fois.
CALL assistant.copy(21);
TRUNCATE public.rental
SELECT count(rental_id) FROM mysql.rental WHERE rental_id > 0
INSERT INTO public.rental SELECT rental_id, ...
FROM mysql.rental WHERE rental_id > 0 ORDER BY rental_id LIMIT 1000
...
...
INSERT INTO public.rental SELECT rental_id, ...
FROM mysql.rental WHERE rental_id > 16005 ORDER BY rental_id LIMIT 1000
INSERT INTO public.rental SELECT rental_id, ...
FROM mysql.rental WHERE rental_id > 16049 ORDER BY rental_id LIMIT 1000
CALL
Dès qu’une requête ne retourne plus aucune ligne, l’assistant considère que le
transfert est terminé. La table job est mise à jour à chaque itération pour
suivre la dernière valeur de la séquence de clé primaire.
SELECT target, lastseq FROM assistant.job
WHERE stage_id = 3 AND target = 'public.rental'::regclass;
target | lastseq
---------------+---------
public.rental | 16049
En cas d’interruption, il est possible de relancer le transfert en appelant
la méthode copy() avec le même identifiant de tâche. L’assistant se charge de
reprendre le transfert à partir de la dernière valeur de clé primaire connue.
CALL assistant.copy(21);
NOTICE: Executing: SELECT count(rental_id) FROM mysql.rental
WHERE rental_id > 16049
NOTICE: Executing: INSERT INTO public.rental SELECT rental_id, ...
FROM mysql.rental WHERE rental_id > 16049
ORDER BY rental_id LIMIT 1000
CALL
Conclusion
La conception d’un tel outil était un petit défi personnel dans la droite lignée de mes recherches autours de la migration vers PostgreSQL avec l’aide exclusive des Foreign Data Wrappers. Ma principale source d’inspiration reste le projet Ora2Pg, l’un des outils open-source le plus complet à ce jour.
J’ai conscience des limites techniques de cet assistant, et du bricolage qu’il reste à mettre en place pour faciliter la vie d’un consultant comme moi. Dans un autre article, j’aimerais présenter un autre outil nommé dispatch que je maintiens depuis quelque temps et avec lequel je réponds aux questions d’orchestration et traçabilité des étapes de la migration.
En prenant un peu de recul, les concepts de base sont là, n’importe quel autre outil dans d’autres langages pourrait parfaitement émerger et enrichir l’écosystème open-source dans la quête de la migration vers PostgreSQL.