Le partitionnement par UUID v7
- 10 minutes de lecture
Au dernier PG Day 2025, j’ai pris la parole pour présenter une méthode de conception que je juge mature et astucieuse : le partitionnement temporel avec le type UUID et sa version 7.
Le support de présentation est disponible à cette adresse et je reprendrais dans cet article, les exemples en guise de démonstration. Je vous propose de passer en détail ce que j’ai pu y dire, et ne pas y dire faute de temps. Également, je vous invite à lire ou redécouvrir mes recherches sur le partitionnement par hachage.
Explorer les limites
En première lecture de la documentation, nous pouvons prendre conscience que le choix de la clé de partitionnement est crucial pour parvenir au meilleur compromis stockage/performance. Parmi les contraintes qui s’imposent à nous, l’une d’entre elles est particulièrement fondamentale :
Pour créer une contrainte d’unicité ou une clé primaire sur une table partitionnée, la clé de partitionnement ne doit pas inclure des expressions ou des appels de fonction, et les colonnes de la contrainte doivent inclure toutes les colonnes de la clé de partitionnement. Cette limitation existe parce que les index individuels créant la contrainte peuvent seulement forcer l’unicité sur leur propre partition ; de ce fait, la structure même de la partition doit garantir qu’il n’existe pas de duplicats dans les différentes partitions.
Documentation : https://www.postgresql.org/docs/current/ddl-partitioning.html
En résumé, si nous souhaitons une contrainte de clé primaire sur notre table partitionnée, il nous faut y inclure la colonne présente dans la clé de partitionnement.
Voyons par l’exemple l’application de cette règle. Un des nombreux cas concernés
par cette limitation est le partitionnement par date, à des fins de purges ou
d’archivage. Une contrainte de clé primaire est requise pour identifier chaque
ligne et un champ timestamp est utilisé pour catégoriser les lignes selon leur
date de création.
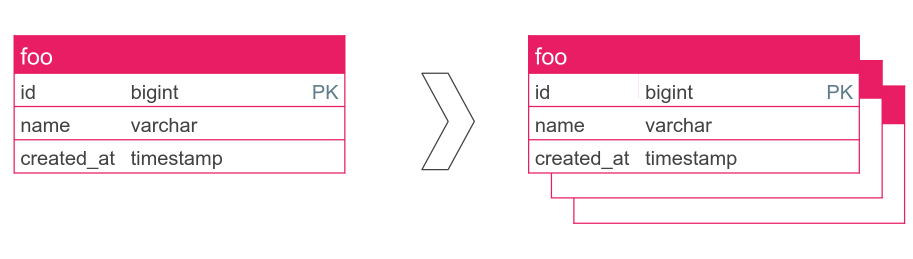
CREATE TABLE foo (
id bigint NOT NULL,
name varchar,
created_at timestamp NOT NULL
) PARTITION BY RANGE (created_at);
-- CREATE TABLE
ALTER TABLE foo ADD PRIMARY KEY (id);
-- ERROR: unique constraint on partitioned table must include all
-- partitioning columns
-- DETAIL: PRIMARY KEY constraint on table "foo" lacks column "created_at"
-- which is part of the partition key.
Pour respecter l’unicité entre toutes les partitions, PostgreSQL se simplifie la tâche en renforçant la contrainte au moment de la distribution des lignes dans les partitions. Ainsi, chaque partition dispose d’un index unique pour le respect de la contrainte d’identité, sans se soucier d’un risque de collision entre deux lignes de partitions différentes.
Reprenons notre exemple pour y entrevoir les dérives qu’apporte ce choix de
modélisation. Ici, nous respecterons à la lettre ce que PostgreSQL nous impose,
à savoir : inclure la colonne created_at dans la contrainte de clé primaire.
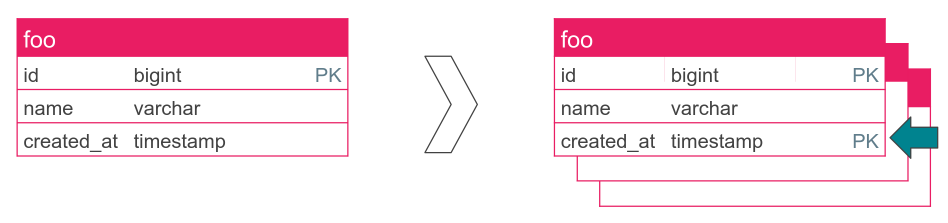
ALTER TABLE foo ADD PRIMARY KEY (id, created_at);
-- ALTER TABLE
CREATE TABLE foo_p202506 PARTITION OF foo
FOR VALUES FROM ('2025-06-01') TO ('2025-07-01');
-- CREATE TABLE
CREATE TABLE foo_default PARTITION OF foo DEFAULT;
-- CREATE TABLE
Avec ce choix, il devient possible d’insérer deux valeurs id identiques, pour
peu que leurs dates de création soient différentes. L’identité n’est donc plus
un simple numéro, mais un couple id, timestamp à questionner systématiquement
lors d’une consultation avec la clause WHERE.
INSERT INTO foo (id, created_at)
VALUES (1, '2025-06-04'), (1, '2024-01-01');
-- INSERT 0 2
SELECT tableoid::regclass partname, id, created_at FROM foo;
-- partname | id | created_at
-- -------------+----+---------------------
-- foo_p202506 | 1 | 2025-06-04 00:00:00
-- foo_default | 1 | 2024-01-01 00:00:00
Les choses empirent lorsqu’une relation de clé étrangère s’immisce dans le casse-tête de la modélisation. En effet, le maintien de l’identité composite d’une ligne se révèle acrobatique, lors de la rédaction des requêtes SQL d’insertion et de jointure.
CREATE TABLE bar (
id bigint PRIMARY KEY,
data text,
created_at timestamp NOT NULL,
foo_id bigint,
foo_created_id timestamp,
FOREIGN KEY (foo_id, foo_created_id)
REFERENCES foo (id, created_at)
);
-- CREATE TABLE
WITH foo_insert AS (
INSERT INTO foo (id, name, created_at)
VALUES (2, 'foo', clock_timestamp())
RETURNING id, created_at
) INSERT INTO bar (id, data, created_at, foo_id, foo_created_id)
SELECT 1, 'bar', clock_timestamp(), f.id, f.created_at
FROM foo_insert AS f;
-- INSERT 0 1
SELECT bar.id, bar.created_at, data, foo.id, foo.name
FROM bar
JOIN foo
ON foo.id = bar.foo_id
AND foo.created_at = bar.foo_created_id;
-- id | created_at | data | id | name
-- ----+----------------------------+------+----+------
-- 1 | 2025-06-16 20:12:02.101194 | bar | 2 | foo
L’exercice devient catastrophique lorsque la seconde table requiert d’être partitionnée à son tour, et où le risque de mauvaise rédaction des requêtes augmente selon le degré de connaissance du modèle par les équipes de développement. Nous retiendrons que cette pratique n’a pas cours et se conclut fréquemment par un retour arrière.
La version 7 du type UUID
La RFC 9562 voit le jour en mai 2024 et propose d’étendre le type de données UUID de trois nouvelles versions (6, 7 et 8). Un UUID (ou Universally Unique IDentifier) est une donnée encodée sur 16 octets, garantissant une unicité à travers le temps (son heure de génération) et l’espace (son serveur de génération). Les UUID sont redoutables dans un contexte de systèmes distribués où chaque participant peut créer de la donnée (une ligne) sans risque de collision avec une autre donnée.
La structure d’un UUID v7 se voit doté d’un timestamp UNIX d’une précision à la milliseconde, encodé dans les 48 premiers bits de sa valeur. Cette version est un compromis entre la randomicité et la praticité. Les bénéfices vous paraîtront limpides à l’issue de cet article.
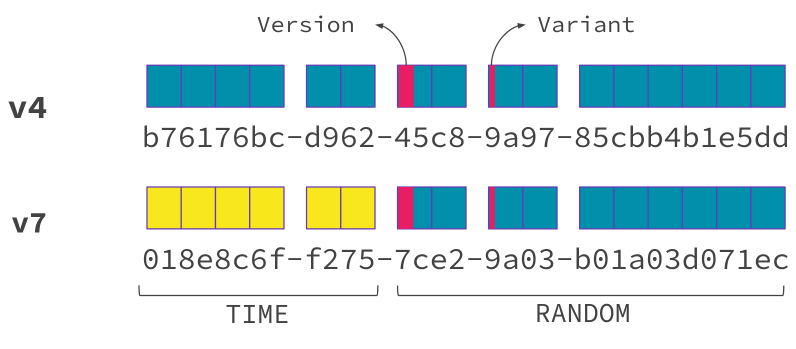
La version 7 était unanimement attendue, car elle apporte une réponse bien plus appropriée pour l’indexation dans les bases de données, offrant à la fois une unicité et une sortabilité pour les champs. Auparavant, l’indexation sur une donnée UUID v4 était désastreuse pour le cache et la fragmentation. Avec cet accroissement monotone des UUID au fil du temps, la gestion interne d’un index B-Tree se voit naturellement facilitée avec un équilibrage moins fréquent et une prédictibilité dans ses performances.
Une publication récente annonçait des gains significatifs entre la version 4 et la version 7, sur les insertions, les consultations par index ainsi que sur l’espace occupé par les tables et les index. De quoi se réconcilier avec le type UUID !
| Metric | UUIDv4 | UUIDv7 | Improvement |
|---|---|---|---|
| Insert Time (10M rows) | 5 min 35 sec | 3 min 38 sec | ~35% faster |
| Table Size | 3618 MB | 3443 MB | ~5% smaller |
| Index Size | 776 MB | 602 MB | ~22% smaller |
| Point Lookup Latency | 0.167 ms | 0.038 ms | ~4x faster |
| Range Scan Latency | 8.284 ms | 3.791 ms | ~2x faster |
La communauté de développement de PostgreSQL a suivi l’actualité de cette RFC, en proposant un premier patch en février 2023 alors que le brouillon de l’Internet Engineering Task Force (IETF) venait d’être publié. C’est lors du CommitFest de janvier 2025 que le sujet est clôturé avec l’ajout dans le commit 78c5e14 de deux méthodes pour la version 18, annoncée à l’automne prochain.
author Masahiko Sawada <msawada@postgresql.org>
Wed, 11 Dec 2024 23:54:41 +0000 (15:54 -0800)
committer Masahiko Sawada <msawada@postgresql.org>
Wed, 11 Dec 2024 23:54:41 +0000 (15:54 -0800)
Add UUID version 7 generation function.
This commit introduces the uuidv7() SQL function, which generates UUID
version 7 as specified in RFC 9652. UUIDv7 combines a Unix timestamp
in milliseconds and random bits, offering both uniqueness and
sortability.
This commit also expands the uuid_extract_timestamp() function to
support UUID version 7.
Additionally, an alias uuidv4() is added for the existing
gen_random_uuid() SQL function to maintain consistency.
Vous me voyez venir ? À l’aide de cette nouvelle RFC, il devient possible de
disposer d’une colonne d’identité contenant une valeur temporelle et qui devient
de facto, une candidate idéale pour la clé de partitionnement. Le tout sans
surcoût pour le stockage, car chaque champ UUID consommera 16 octets, autant
qu’un bigint (8 octets) et un timestamp (8 octets) réunis !

Partitionner par UUID v7
L’idée originale me vient d’un article de Daniel Vérité, lu l’été dernier, alors même que la RFC venait de sortir, mais que le patch dans PostgreSQL était bloqué par la période de gel avant la sortie de la version 17. Il était question de pouvoir implémenter ses propres méthodes en PL/pgSQL sur les versions en vigueur, sans attendre la version 18.
La création de la table foo se réalise ainsi :
CREATE TABLE foo (
id uuid PRIMARY KEY DEFAULT uuidv7(),
name varchar
) PARTITION BY RANGE (id);
-- CREATE TABLE
CREATE TABLE foo_p202506 PARTITION OF foo
FOR VALUES FROM (uuidv7_boundary('2025-06-01'))
TO (uuidv7_boundary('2025-07-01'));
-- CREATE TABLE
CREATE TABLE foo_default PARTITION OF foo DEFAULT;
-- CREATE TABLE
La méthode uuidv7_boundary est inédite et n’a pas d’équivalent dans les
versions à venir de PostgreSQL, bien qu’elle mériterait amplement sa place. Sa
définition est disponible sur le dépôt dverite/postgres-uuidv7-sql.
CREATE FUNCTION uuidv7_boundary(timestamptz) RETURNS uuid
AS $$
/* uuid fields: version=0b0111, variant=0b10 */
select encode(
overlay('\x00000000000070008000000000000000'::bytea
placing substring(
int8send(
floor(extract(epoch from $1) * 1000)::bigint) from 3)
from 1 for 6),
'hex')::uuid;
$$ LANGUAGE sql stable strict parallel safe;
Grâce à cette fonction, il est possible d’obtenir les bornes d’une partition en
ne conservant que la donnée temporelle d’un UUID et en remplissant le reste par
des zéros (et quelques bits fixes). Pour la table foo, on se retrouve dès lors
avec la partition qui respecte les valeurs comprises entre juin et juillet.
Partitioned table "public.foo"
Column | Type | Collation | Nullable | Default
--------+-------------------+-----------+----------+----------
id | uuid | | not null | uuidv7()
name | character varying | | |
Partition key: RANGE (id)
Indexes:
"foo_pkey" PRIMARY KEY, btree (id)
Partitions: foo_p202506 FOR VALUES
FROM ('0197285b-e300-7000-8000-000000000000')
TO ('0197c2da-ab00-7000-8000-000000000000'),
foo_default DEFAULT
INSERT INTO foo (name) VALUES ('foo');
-- INSERT 0 1
SELECT tableoid::regclass partname, *,
uuid_extract_timestamp(id) created_at
FROM foo \gx
-- -[ RECORD 1 ]------------------------------------
-- partname | foo_p202506
-- id | 01977a44-364a-752a-b62e-c026ac2f930d
-- name | foo
-- created_at | 2025-06-16 21:43:00.17+02
Une pratique en bonne voie
Au cours de ma prise de parole, le temps m’avait manqué pour conclure. Les adeptes de l’extension pg_partman ne seront pas complètement réjouis d’apprendre que le support du partitionnement automatique pour une colonne de type UUID est partiellement implémenté.
La gestion de types text et uuid a été apportée en novembre 2024,
permettant ce genre de magie pour provisionner un certain nombre de partitions.
Les fonctions partman.uuid7_time_encoder et partman.uuid7_time_decoder sont
équivalentes respectivement aux fonctions précédentes uuidv7_boundary et
uuid_extract_timestamp.
CREATE TABLE foo (
id uuid PRIMARY KEY DEFAULT uuidv7(),
name varchar
) PARTITION BY RANGE (id);
-- CREATE TABLE
SELECT partman.create_parent(
p_parent_table := 'public.foo',
p_control := 'id',
p_interval := '1 month',
p_time_encoder := 'partman.uuid7_time_encoder',
p_time_decoder := 'partman.uuid7_time_decoder'
);
-- create_parent
-- ---------------
-- t
Cependant, le déplacement automatique des lignes de la partition default vers
une autre au cours de la maintenance par partition_data_time() provoque encore
une erreur à l’heure de la rédaction de cet article. La PR 739, proposée
en janvier dernier, tente de corriger en grande partie les angles morts des
travaux engagés.
SELECT * FROM partman.partition_data_time(
p_parent_table => 'public.foo'
);
-- ERROR: Cannot run on partition set without time
-- based control column or epoch flag set with
-- an id column. Found control: uuid, epoch: none
-- CONTEXT: PL/pgSQL function partman.partition_data_time()
-- line 63 at RAISE
Le mot de la fin
Les articles que j’ai énoncés précédemment me conforte dans l’idée que le type UUID dans sa version 7 est une belle opportunité pour l’adoption de PostgreSQL, notamment pour ce cas d’usage du partitionnement par date.
L’accueil que cette rapide présentation a reçu m’a fait également l’effet d’un appel d’air par l’audience, voyant dans l’UUID un moyen de pousser les limites du moteur de base de données relationnel et open-source le plus avancé au monde.