A brief history of backup label
- 11 minutes to read
For a long time, I remained ignorant about transaction logging mechanisms and PITR in PostgreSQL, although they were crucial in data durability. A better understanding of these concepts would have helped me in a previous life, to be more confident during a backup configuration and, well, during after-crash intervention!
By reading this post, I will come back to an amusing file that used to be a topic of discussion over the past decade: the backup label file. What is it and what is it used for? How has it be enhanced from its origin with PostgreSQL 8.0 and what could be expected from him over the next years?
Once upon a time there was transaction logging
As an introduction and to better understand this post, it seems good to me to
explain that each changing operation in PostgreSQL, like an UPDATE or an INSERT,
is written a first time on COMMIT in a group of files, which is called WAL
or transaction logs. Taken together, these changes represent a low cost to
disk activity compared to random writings of others processes at work in PostgreSQL.
Among them, the checkpointer process ensures that new data in memory is permanently
synchronized in the data files and that at regular times called CHECKPOINT. This
on-disk two-step writing provides excellent performance and ensures that modified
blocks are not lost when a transaction ends successfully.
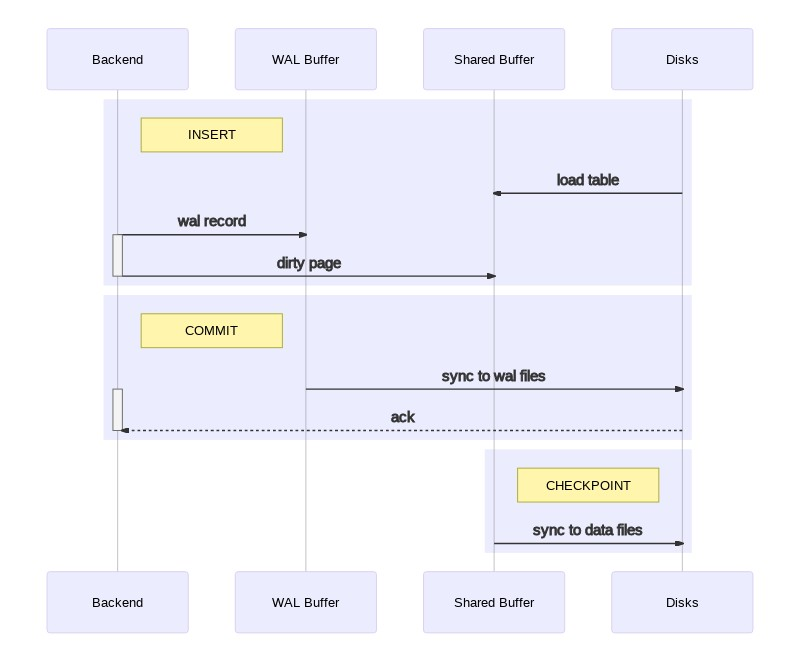
Because of transaction logging, all data files of our cluster are late on real
transactional workload, until the next CHECKPOINT moment. In case of an unexpected
interruption (like a memory crash), dirty pages will be lost and data files are
called inconsistents, as they contain data that can be too old or uncommitted.
In such situations, cluster service will be able to restart by applying losted changes thanks to transaction logs written in WAL files. This rebuilding process of data files to their consistent state is simply called crash recovery.
Whether after a crash or data restoration, data files must be consistent during the startup stage in order to accept write access to data again. What a terrible surprise when the startup fails with the following error:
PANIC: could not locate a valid checkpoint record
At this moment of startup stage, the cluster does not find any consistent point between data files and fails to look after the nearest checkpoint record. Without transactions logs, crash recovery fails and stops. At this point, your nerves and your backup policy are put to the test.
To put it another way: in lacks of WAL or theirs archives, your most recent data is lost.
… And pg_resetwal will not bring them back to you.
And comes backup label
After this lovely warning, we will consider that the archiving of transaction logs is no longer an option when you are making backups. Make sure that these archives are stored in a secure place, or even a decentralized area so that they are accessible by all standby clusters when you need to trigger your failover plan.
For those who have reached this part of the post, you should not be too lost if I tell you that the backup label file is a component of a larger concept called: backup.
The backup history file is just a small text file. It contains the label string you gave to
pg_basebackup, as well as the starting and ending times and WAL segments of the backup. If you used the label to identify the associated dump file, then the archived history file is enough to tell you which dump file to restore.Source: Making a Base Backup
Let’s see the simplest behavior of this documentation-praised tool pg_basebackup
by creating a tar archive of my running cluster.
$ pg_basebackup --label=demo --pgdata=backups --format=tar \
--checkpoint=fast --verbose
pg_basebackup: initiating base backup, waiting for checkpoint to complete
pg_basebackup: checkpoint completed
pg_basebackup: write-ahead log start point: 0/16000028 on timeline 1
pg_basebackup: starting background WAL receiver
pg_basebackup: created temporary replication slot "pg_basebackup_15594"
pg_basebackup: write-ahead log end point: 0/16000100
pg_basebackup: waiting for background process to finish streaming ...
pg_basebackup: syncing data to disk ...
pg_basebackup: renaming backup_manifest.tmp to backup_manifest
pg_basebackup: base backup completed
Since version 10, option --wal-method is setted on stream by default, which
means that all present and future WAL segments in subdirectory pg_wal will be
written in a dedicated archive next to the backup, thanks to a temporary
replication slot.
Since version 13, this tool creates a new manifest backup file in order to verify the integrity of our backup with pg_verifybackup. Let’s explore our working directory to find our long awaited backup label.
$ tree backups/
backups/
├── backup_manifest
├── base.tar
└── pg_wal.tar
$ tar -xf backups/base.tar --to-stdout backup_label
START WAL LOCATION: 0/16000028 (file 000000010000000000000016)
CHECKPOINT LOCATION: 0/16000060
BACKUP METHOD: streamed
BACKUP FROM: master
START TIME: 2021-01-18 15:22:52 CET
LABEL: demo
START TIMELINE: 1
This file is located in root’s archive and will be useful in startup process of
our cluster, since it contains the checkpoint information needed on a recovery
situation. In above example, the sequence number (LSN) is 0/16000060 and will
be found in WAL 000000010000000000000016. In a lack of a backup label file,
startup process will only have the control file to obtain the most recent
checkpoint, with no guarantee that it is the right one.
The glory age
You will agree with me that content and interest of the backup label file are anecdotal (though essential) in backup architecture with PostgreSQL. It is (just) a few-lines text file, only needed in some recovery processes.
And yet, this small revolution caused by version 8.0 in January 2005 with its new functionality, continuous archiving and PITR mecanism, aroused the creativity of development team in the years that followed. The backup label evolved to gain modularity and stability.
At this time, pg_backbackup was not yet available, and only an explicit call
to the function pg_start_backup() allowed you to generate the backup_label
file in which were the following four entries to support hot backup:
# backend/access/transam/xlog.c
fprintf(fp, "START WAL LOCATION: %X/%X (file %s)\n",
startpoint.xlogid, startpoint.xrecoff, xlogfilename);
fprintf(fp, "CHECKPOINT LOCATION: %X/%X\n",
checkpointloc.xlogid, checkpointloc.xrecoff);
fprintf(fp, "START TIME: %s\n", strfbuf);
fprintf(fp, "LABEL: %s\n", backupidstr);
All next versions brought various fixes or enhancements. Among the notable contributions, I selected for you:
Contribution from Laurenz Albe (commit c979a1fe)
Published with 8.4 version,
xlog.ccodefile is extended with an internal method to cancel a running backup. Calling thepg_ctl stopcommand in fast mode renames the file tobackup_label.old;Contribution from Dave Kerr (commit 0f04fc67)
Appeared with 9.0.9 minor version, the
pg_start_backup()method includes afsync()call ensures the backup label to be written to disk. This commit guarantees the consistency of the backup during an external snapshot;Contribution from Heikki Linnakangas (commit 41f9ffd9)
Proposed in 9.2, this patch fix abnormal behaviors on restoration from the streaming backup functionality. Backup label contains a new line that specify the method used between
pg_start_backuporstreamed;Contribution from Jun Ishizuka and Fujii Masao (commit 8366c780)
With 9.2 and above,
pg_start_backup()can be executed on a secondary cluster. The role (standbyormaster) of the instance from which the backup comes is retained in the backup label;Contribution from Michael Paquier (commit 6271fceb)
Added in 11, a new timeline entry in backup label file joined the previous information to compare its value with thoses contained in WAL needed by recovery process;
As you may understand, during an amount of years, the ability to take a consistent
backup leaded on two distinct ways: pg_start_backup() and pg_basebackup. The
first and historical one was deeply impacted by regular commentaries about an
unwanted behavior with it “exclusive” mode.
Let us look at an example with PostgreSQL 13:
SELECT pg_start_backup('demo');
-- pg_start_backup
-- -----------------
-- 0/1D000028
$ kill -ABRT $(head -1 data/postmaster.pid)
$ cat data/backup_label
START WAL LOCATION: 0/1D000028 (file 00000001000000000000001D)
CHECKPOINT LOCATION: 0/1D000060
BACKUP METHOD: pg_start_backup
BACKUP FROM: master
START TIME: 2021-01-18 16:49:57 CET
LABEL: demo
START TIMELINE: 1
The ABRT signal interrupts the postmaster process of the cluster in the
violent way and an internal routine, called CancelBackup, won’t be triggered
correctly in order to rename our backup label to backup_label.old. On a normal
production workload, all transactions logs are recycled or even archived as
activity involves more new transactions. On restart of our interrupted instance,
the backup label inside data directory will be read by mistake with an errouneous
checkpoint record requested by the recovery process.
LOG: database system was shut down at 2021-01-18 17:08:43 CET
LOG: invalid checkpoint record
FATAL: could not locate required checkpoint record
HINT: If you are restoring from a backup, touch "data/recovery.signal"
and add required recovery options.
If you are not restoring from a backup, try removing the file
"data/backup_label".
Be careful: removing "data/backup_label" will result in a corrupt
cluster if restoring from a backup.
LOG: startup process (PID 19320) exited with exit code 1
LOG: aborting startup due to startup process failure
LOG: database system is shut down
The complete message only appeared with PostgreSQL 12 as an explicite warning in documentation of the backup label, following long discussions on throwing away this particular mode or not. In one of theses threads, we can read a remarquable advocacy written by Robert Haas who looks back on the success of this feature since its creation and points out the frequent confusion encountered by users who do not understand either complexity or clear instructions from the documentation.
From these days of darkness, a dedicated note has been added.
This type of backup can only be taken on a primary and does not allow concurrent backups. Moreover, because it creates a backup label file, as described below, it can block automatic restart of the master server after a crash. On the other hand, the erroneous removal of this file from a backup or standby is a common mistake, which can result in serious data corruption.
Next generation
This well-known drawback has been addressed by the development team in september 2016 when releasing PostgreSQL 9.6 with “non-exclusive” backups. Since then, exclusive backup mode is tagged as deprecated by developers and could be removed in future versions.
Backup label file has not been removed. Its content is still relevant in case of
point-in-time recovery, but it loses that transitory state on disk and won’t be
written in data directory on pg_start_backup() call. Instead, administrator or
backup script must keep session opened until pg_stop_backup() call in order to
collect backup’s metadata and rebuild backup label file needed by restoration
process.
SELECT pg_start_backup(label => 'demo', exclusive => false, fast => true);
-- pg_start_backup
-- -----------------
-- 0/42000028
SELECT labelfile FROM pg_stop_backup(exclusive => false);
-- labelfile
-- ----------------------------------------------------------------
-- START WAL LOCATION: 0/42000028 (file 000000010000000000000042)+
-- CHECKPOINT LOCATION: 0/42000060 +
-- BACKUP METHOD: streamed +
-- BACKUP FROM: master +
-- START TIME: 2021-01-18 18:17:16 CET +
-- LABEL: demo +
-- START TIMELINE: 1 +
There is another easy way to retrieve this content, especially if archiving is
configured. At the end of backup, metadata are written in a history file .backup
inside pg_wal and a .ready file is added in archive_status directory,
waiting for archiving. A quick search into our WAL repository can lead us to a
ready-to-use file.
$ find archives -type f -not -size 16M
archives/000000010000000000000016.00000028.backup
$ grep -iv ^stop archives/000000010000000000000016.00000028.backup
START WAL LOCATION: 0/42000028 (file 000000010000000000000042)
CHECKPOINT LOCATION: 0/42000060
BACKUP METHOD: streamed
BACKUP FROM: master
START TIME: 2021-01-18 18:17:16 CET
LABEL: demo
START TIMELINE: 1
With a fresh new architecture for non-exclusive concurrent backup system, various
backup tools have emerged, more powerful and modular than pg_basebackup. Among
well-known third-party tools, you might hear of pgBackRest written in C,
Barman written in Python, or even pitrery written in Bash. Moreover, these
tools do a pretty well-done job, avoiding a painful effort for every administrator
in maintaining their complex scripts.
Moral of the story
Over releases, backup label file has endured many storms and twists to result in a more elegant way to perform physical backup and restoration with PostgreSQL.
If you are administrating database cluster, especially in virtualized engine,
I warmly recommend you to check your backup policies and associated tools. It is
not so uncommon for hypervisors to take a system snapshot in exclusive mode
with pg_start_backup() as a pre-hook.
Above specialized third-party softwares could/must be tested. If they do not fit
your needs, you may study others tricks to make our backups in a concurrent way,
as this example with a temporary file made by mkfifo command.
Old-fashion exclusive backup is deprecated but not removed (yet). It is a real concern that remains in a standstill, since last Commitfest in July 2020. In a thread, contributor David Steele (who made pgBackRest, by the way) suggested that backup label content could be stored in memory to fix its main wickness:
It might be easier/better to just keep the one exclusive slot in shared memory and store the backup label in it. We only allow one exclusive backup now so it wouldn’t be a loss in functionality.
To be continued!