Transfer modes in a migration
- 7 minutes to read
In computer science, a migration project involves changing one or more technical components without impacting any application behaviors. In the realm of databases (and the profession I practice), it will involve choosing a new system (such as PostgreSQL) to replace another (such as Oracle or Microsoft SQL Server).
In a previous article (French), I described exhaustive steps to perform a complete migration using Foreign Data Wrappers technology. However, the critical data transfer step described there does not suit all situations. Let’s explore together the alternatives that cover a large portion of the needs.
Transfer without a network
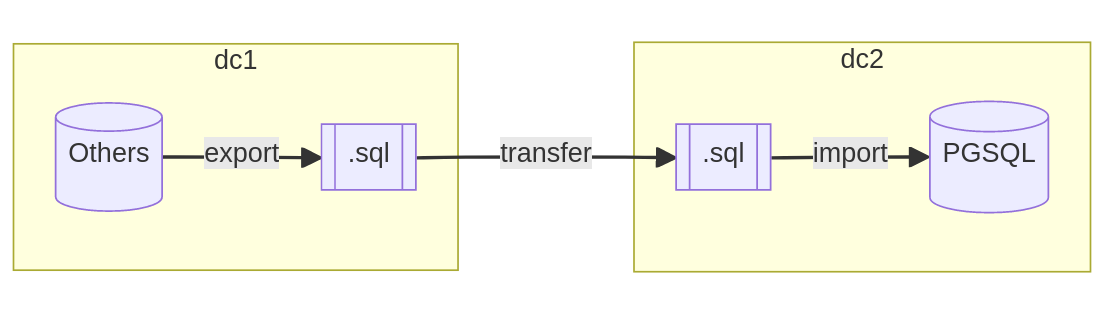
Several reasons can justify that the two servers are not in direct connection with each other. This includes the prohibition of opening access to the source instance from the internet or the complexity of configuring a secure link (VPN) between the two infrastructures.
In such a scenario, it becomes necessary to dump the data outside the database while ensuring the consistency of the data. A physical backup of the database or an export in SQL format are reliable means to consolidate a complete archive of the database.
The transfer step is carried out according to the imagination of the teams. The simplest method is to transfer to an SFTP repository provided by the second data center or any other protocol that checks the integrity of the archive once transferred. The most unlikely method I have observed was the physical movement of a copy of the archive by a specialized courier company, by car, scooter, or plane depending on the distance to cover.
Once the archive is received by the teams and deemed intact, it may be necessary to import the data into a buffer database, provided that the file format (SQL or proprietary) is not yet compatible with PostgreSQL. From this precise moment, it is then possible to import the data into the target database respecting the order of object creations and data insertion.
Operation Summary:
- Very high downtime (from several hours to several days);
- Implementation complexity is low with the right tools;
- Risk of data consistency issues is very low if integrity checks are performed at each step.
Transfer with intermediary
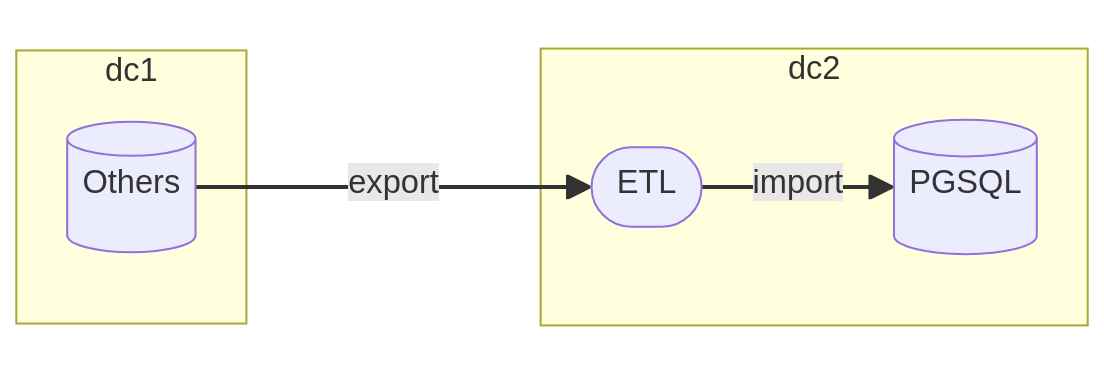
When the systems are hosted in the same location, setting up routing rules allows for easier connection between the two servers. Among the migration tools, we find the family of ETL (Extract Transform Load) tools that act as intermediaries between the two databases.
These tools provide a large number of connection drivers as well as data transformation methods to orchestrate migration without the need to export any table to a flat file. The bulk of the work is done in memory and with the help of multiple processors to speed up transfer operations.
Although specialized for migrations to PostgreSQL, I classify the open-source
tool Ora2Pg in the category of ETL. It precisely meets the previous
definition by opening multiple connections to the source instance to read tables
in batches of 10,000 rows (using the DATA_LIMIT directive) and opening other
connections to the target instance to insert them with COPY instructions,
thanks to the pg_putcopydata method of the DBD::Pg driver.
Operation Summary:
- High downtime (several hours);
- Low implementation complexity with the right tools;
- Very low risk to data consistency.
Direct transfer
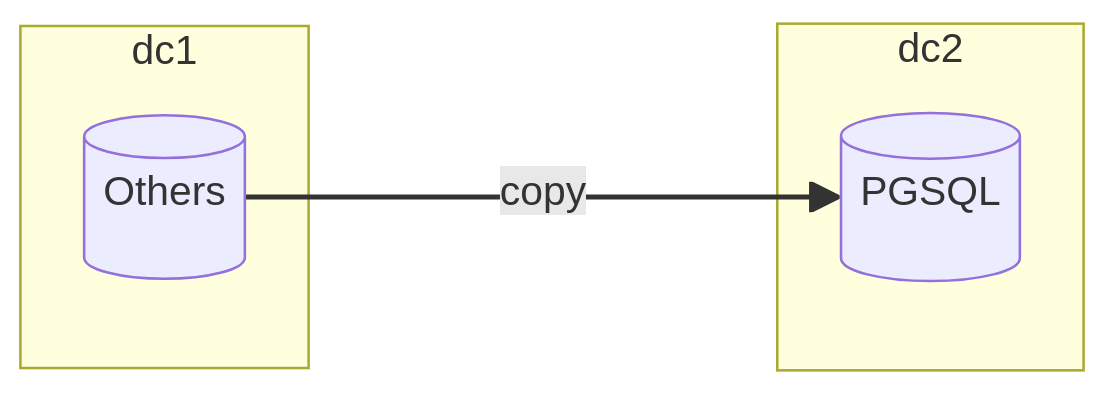
This mode should feel familiar if you are a regular reader (subscribe!) because direct transfer between a third-party system and PostgreSQL relies on the technology of Foreign Data Wrappers.
This solution opens a direct channel between the PostgreSQL instance and the remote instance through external tables. Thus, it becomes possible to query the data with SQL, provided that a wrapper has been developed to communicate with the correct driver.
The extraction, transfer, and insertion operations are performed in the same
transaction: it’s a simple INSERT INTO SELECT query. This method is
faster than the previous mode since it eliminates a resource-intensive
intermediary (ETL).
Although appealing, copying through a wrapper can be particularly slow for large data (such as Oracle’s BLOBs) because they have a different structure. It is then necessary to mix solutions: one with a direct transfer for tables without large data and the other with an ETL to optimize the volume of rows and the amount of memory to allocate.
Operation Summary:
- Downtime: High (from several minutes to several hours);
- Implementation Complexity: Low to High for large data;
- Risk to Data Consistency: Very Low.
Partial catch-up transfer
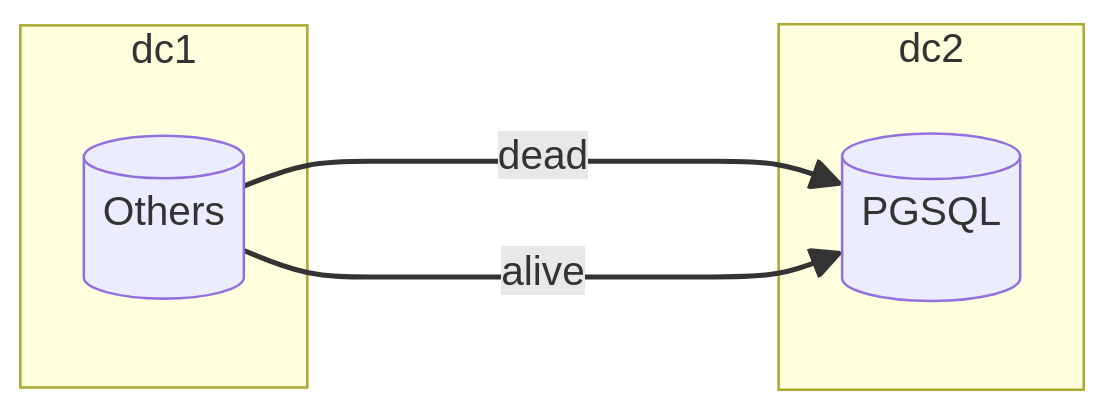
For very large volumes where service interruption must be kept to a minimum, the solutions mentioned above can be very limiting. Exporting/importing the entire dataset is a lengthy and unavoidable step.
What I refer to as the “partial catch-up transfer” involves identifying the
largest tables with mostly dead rows. It requires assurance that no UPDATE or
DELETE modifications occur from the development team and that the table has a
primary key where new values during an insertion are always greater than the
previous.
Thus, an initial copy of the data can be performed live, without service interruption, where only the dead rows will be moved to the new system. Depending on the proportion of the complete volume, this step can save dozens of hours in the final operation. In addition to the transfer operations, it is necessary to maintain a register of primary key values that separates dead data from live (or upcoming) data. For each table, this value will be a kind of checkpoint for the catch-up phase.
During the crucial switch step, all live tables will be entirely copied, and the rows from dead tables whose key is greater than the memorized value will be selected and then inserted into their respective table. A preliminary study must determine whether indexes deserve to be created during the first or second transfer step, depending on the effective time they save or consume throughout the entire operation.
Operation Summary:
- Low downtime (several tens of minutes);
- High implementation complexity;
- High risk of data consistency issues if the development team does not provide sufficient guarantees in choosing dead tables.
Transfer with transaction replay
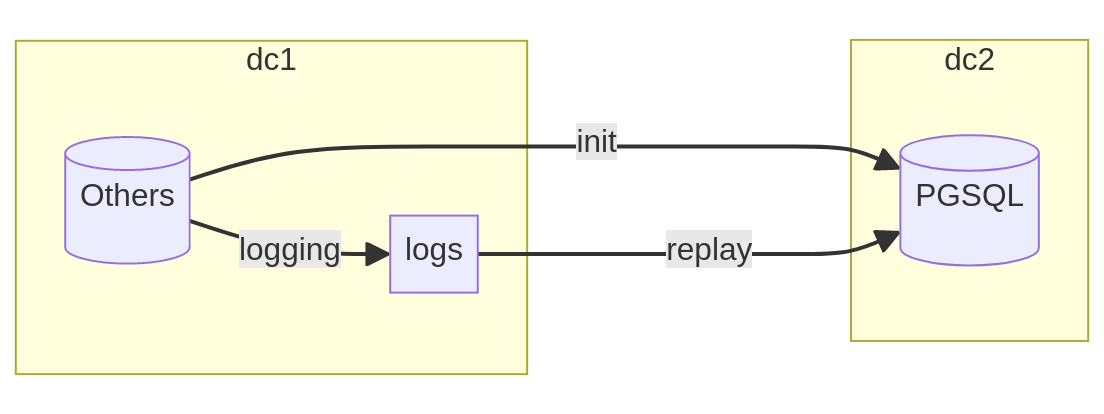
Speaking of “transaction replay” is essentially referring to physical replication or logical replication. Each system has its own mechanisms, and the tools to implement them can vary. I recommend looking into excellent projects like ora_migrator, which implements replication using triggers with Oracle, and pg_chameleon, which decodes transaction logs from MySQL.
The main advantage of this transfer mode lies in the system’s ability to log all modifications requested and record them in a sequence of transactions. Thus, between time T0 and time T1, it becomes possible to reproduce all changes to achieve a consistent and faithful state.
In this scenario, the operation requires a full and coherent data load into the target database. This initialization phase occurs without service interruption but requires particular care in monitoring disks or system source alerts because capturing data maintains a snapshot that can become costly if the transfer takes too long.
At the end of initialization, the replay can start without penalizing the
production source database’s activity. The tool consumes each event in the order
of arrival to transform it into an insert (INSERT), update (UPDATE), or
delete (DELETE) in the PostgreSQL database. The cutover operation then
consists of prohibiting any new modification to the source system, waiting for
the end of replay, and changing the connection strings so that applications
connect to the new PostgreSQL database.
Operation Summary:
- Very low downtime (a few seconds);
- Implementation complexity is high, even very high depending on the chosen solutions;
- Risk of data consistency issues is very high if the tool fails for a transaction it cannot decode during the replay step.
Freedom of Choice
This comprehensive review had been on my mind for some time, and it seemed necessary to shed light on the various constraints posed by a migration project. In the sphere of consultants I interact with and the open-source projects I actively monitor, I try to convince myself that there could be a universal solution capable of addressing every need and situation outlined in this article.
I deliberately avoided discussing the Debezium project because it relies on many technical components like Kafka, Java, and a myriad of connectors. Although a conference (French) on this topic kept me engaged last June, I haven’t yet had the opportunity to lead a large-scale project that justified such a significant human investment in its implementation.
There are numerous free or paid tools, each with its own purpose and philosophy. Choosing one over another depends on the migration teams and their technical maturity, but ultimately, the choice is free!