An assistant to copy data from a remote server
- 11 minutes to read
During the last PGSession organized by Dalibo, I wrote and led a workshop
(french) on the migration to PostgreSQL using Foreign Data Wrappers, or FDW.
This was an opportunity to present to the general public the db_migrator
extension for which I wrote an article on this blog.
While working on this workshop, we noticed that copying data with the
db_migrator extension is not perfectly supported. Indeed, although there is a
low-level function to distribute the transfer table by table over several
processes, many situations will require writing a large number of SQL queries to
get out of trouble. Over the following months, I worked on the design of an
assistant written in PL/pgSQL whose purpose is to simplify the generation
of these queries.
Data transfer without an assistant
There is no magic in the operation of copying data through a Foreign Data
Wrapper. Everything boils down to a series of INSERT queries that must be
executed in a predefined order. Let’s take the 16 tables of the well-known
“Sakila” data model (available at this address) to illustrate the need for
generating transfer queries.
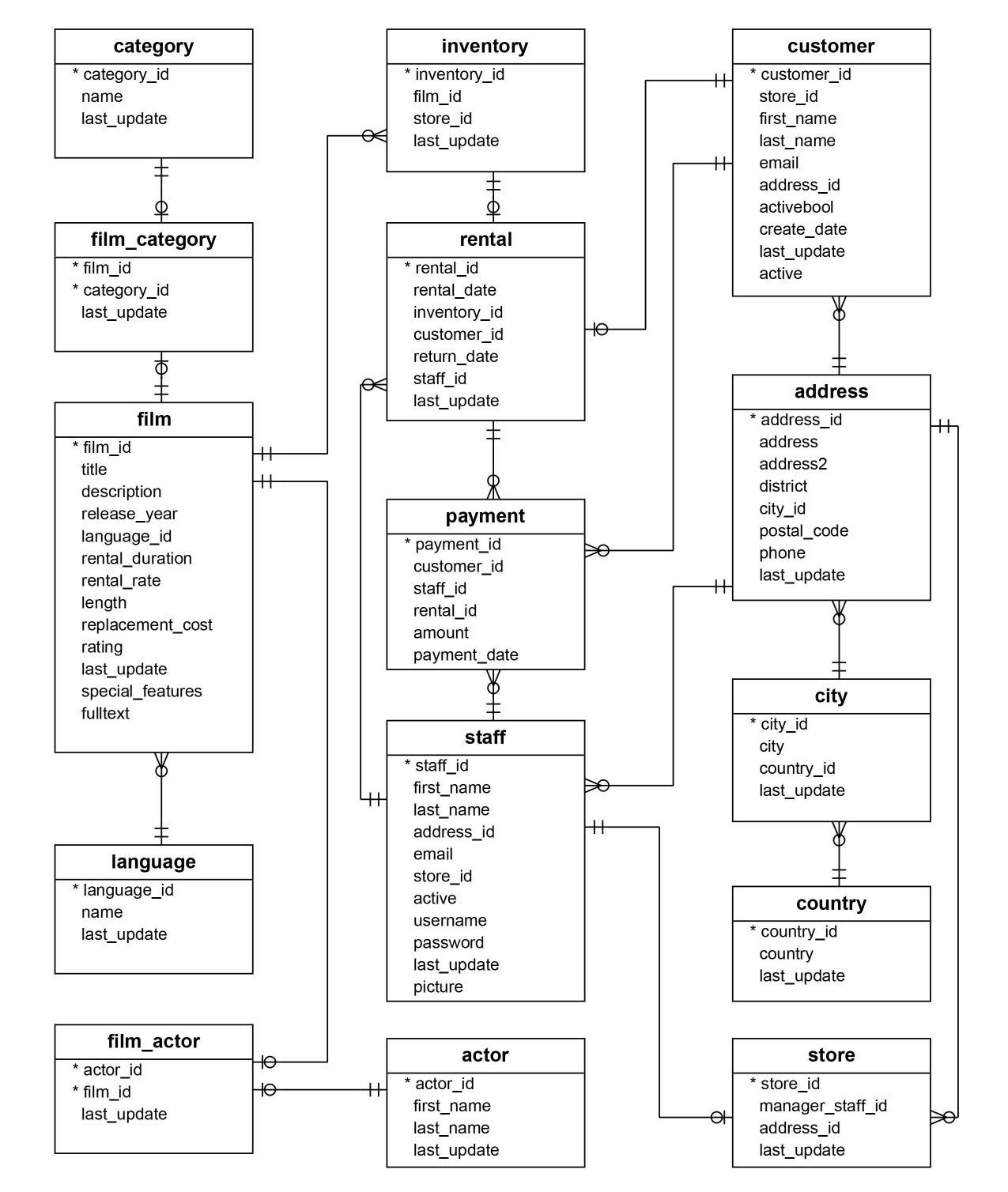
For the purpose of this article, I have a PostgreSQL database with the two following schemas that I will use in my demonstrations:
mysql: the source schema containing the definition of the external tables via themysql_fdwextension;public: the target schema where the data will be copied.
Each external table is subject to a quick study to obtain the correct column
type match, and their definition is kept in an SQL file for the project teams.
For example, the rental foreign tables is defined as follows:
CREATE FOREIGN TABLE mysql.rental (
rental_id integer NOT NULL,
rental_date timestamp without time zone NOT NULL,
inventory_id integer NOT NULL,
customer_id smallint NOT NULL,
return_date timestamp without time zone,
staff_id smallint NOT NULL,
last_update timestamp without time zone NOT NULL
)
SERVER sakila_mysql
OPTIONS (
dbname 'sakila',
table_name 'rental'
);
When creating the public.rental table that will host the data, it is
opportune to decide whether we want to set up partitioning, something that
db_migrator is able to identify and set up. For the example, I take back the
strict structure using the CREATE TABLE LIKE syntax to create all my target
tables.
CREATE TABLE public.actor (LIKE mysql.actor);
CREATE TABLE public.address (LIKE mysql.address);
...
Even before setting up an INSERT query generator, it is easy to see the look
of these queries. Each line of the external table will be read through a global
SELECT, then inserted into the target table. The migration script contains 16
instructions, one for each table.
-- insert.sql
INSERT INTO public.actor SELECT * FROM mysql.actor;
INSERT INTO public.address SELECT * FROM mysql.address;
...
INSERT INTO public.store SELECT * FROM mysql.store;
To benefit from several processes, I appreciate the xargs tool which allows
distributing each line of the insert.sql file on a new psql session. This
technique was presented in the February workshop, especially to parallelize the
construction of indexes and primary keys, defined in an SQL file.
$ xargs -P 4 -a insert.sql -d '\n' -I % sh -c 'psql -c "%"'
INSERT 0 16
INSERT 0 603
...
INSERT 0 16044
This method is not perfect, it lacks verbosity, the SQL queries are static. Anyway, let’s see the next part to discover what my assistant can bring.
Demonstration of the assistant
Unlike my other PL/pgSQL projects, this assistant is not an extension and must be installed as a simple script. Once downloaded, it is sufficient to invoke it on the database of your choice with the following command:
$ psql -d sakila -f fdw-assistant.sql
The default schema is named assistant and contains a configuration table
simply called config. For each table to be migrated, one must insert a single
line that will serve as the starting point for generating data migration
queries. In the current version, we find the following parameters:
source: the external table containing the data to be copied;target: the target table where the data will be copied;pkey: the primary key column of the target table;priority: the lowest values define the tables to be processed first;parts: the number of processes to launch for copying the data;trunc: an option to empty the target table before copying the data;condition: aWHEREclause to filter the data to be copied;batchsize: the number of rows to copy before performing an intermediateCOMMIT.
To initialize this table in the first instance, it is necessary to know at least
the primary key columns of each remote table. By reporting the information from
the relational diagram of the Sakila database, we can fill the config table as
follows:
INSERT INTO assistant.config (source, target, pkey)
VALUES
('mysql.actor', 'public.actor', 'actor_id'),
('mysql.address', 'public.address', 'address_id'),
...
('mysql.store', 'public.store', 'store_id');
For each transfer, we indicate the source and target table, as well as the primary key column. The latter is required to sort the rows, split the transfer into several batches, and restart the transfer in case of interruption.
With this configuration, we can move on to the planning step. The stage
and job tables are fed with new elements that will be used to drive and track
the different transfers to be done.
SELECT * FROM assistant.plan();
target | invocation
---------------+--------------------------
customer | CALL assistant.copy(1);
address | CALL assistant.copy(2);
...
(16 rows)
A view named report allows you to follow the progress of the different steps
by joining the stage and job tables. It provides very useful elements to
monitor the progress and throughput of the transfers.
SELECT target, state, rows FROM assistant.report WHERE stage_id = 1;
target | state | rows
---------------+---------+------
rental | pending | 0
actor | pending | 0
...
(16 rows)
Rows returned by the plan() command can then be invoked one after the
other with the \gexec meta-command of psql, or by using the file technique
and distributing the queries with xargs.
Calling the copy() method is responsible for building the INSERT statement
for copying data from a remote table to a local table. For example, for the
customer table, the result of the call will be as follows:
CALL assistant.copy(1);
NOTICE: Executing: TRUNCATE public.customer
NOTICE: Executing: SELECT count(customer_id) FROM mysql.customer
WHERE customer_id > 0
NOTICE: Executing: INSERT INTO public.customer
SELECT customer_id, store_id, first_name, last_name, email,
address_id, active, create_date, last_update
FROM mysql.customer
WHERE customer_id > 0 ORDER BY customer_id
CALL
At the end of the transfer, the report view provides a summary of the operation.
SELECT * FROM assistant.report
WHERE stage_id = 1 AND target = 'public.customer'::regclass;
-[ RECORD 1 ]-------------------------
stage_id | 1
target | public.customer
job_start | 2024-05-28 10:19:18.334917
state | completed
rows | 599
total | 599
elapsed | 00:00:00.081273
rate | 7370.22
progress | 1.00
eti | 00:00:00
eta | 2024-05-28 10:19:18.334917
Distribution over several processes
As the assistant was designed, I felt the need to enrich the underlying queries
to respond to other recurring use cases in the data migration domain. Among
these, we find the ability to distribute the rows of the same table over several
sessions, each with a WHERE clause based on the result of the Euclidean
division (modulo) of the primary key.
To activate this feature, simply fill in the parts parameter in the config
table. For example, for the film table, we can define:
UPDATE assistant.config SET parts = 4 WHERE target = 'public.film'::regclass;
This configuration takes effect during the next planning. The call to the
plan() method then inserts four lines into the job table for the film
table, each attached to a value between 0 and 3. The condition column is then
enriched for the rows of the task table in view of the next step.
SELECT invocation FROM assistant.plan('{public.film}');
invocation
--------------------------
CALL assistant.copy(17);
CALL assistant.copy(18);
CALL assistant.copy(19);
CALL assistant.copy(20);
(4 rows)
SELECT job_id, job.target, state, part, condition
FROM assistant.job JOIN assistant.task USING (job_id)
WHERE stage_id = 2;
job_id | target | state | part | condition
--------+--------+---------+------+-----------------
17 | film | pending | 0 | film_id % 4 = 0
18 | film | pending | 1 | film_id % 4 = 1
19 | film | pending | 2 | film_id % 4 = 2
20 | film | pending | 3 | film_id % 4 = 3
When calling the copy() method, the assistant builds the INSERT queries
based on the conditions previously defined. For example, for the first part of
the film table, the trace indicates the INSERT queries that were generated.
CALL assistant.copy(17);
NOTICE: Executing: TRUNCATE public.film
NOTICE: Executing: SELECT count(film_id) FROM mysql.film
WHERE film_id > 0 AND film_id % 4 = 0
NOTICE: Executing: INSERT INTO public.film
SELECT film_id, title, description, release_year,
language_id, original_language_id, rental_duration,
rental_rate, length, replacement_cost, rating,
special_features, last_update
FROM mysql.film WHERE film_id > 0 AND film_id % 4 = 0
ORDER BY film_id
CALL
The TRUNCATE operation only occurs for the session whose value of part is
equal to 0. In the nominal case, this session is launched before all the others
to respect the expected behavior in the configuration with the trunc column
(true by default).
The obvious interest of this method is to obtain the best insertion rate for a
given table, relying on the extraction power of the remote server and the
writing capacity of the local server. The rate can be consulted with the
report view, especially to compare two loads for the same table, like the
example of the film table. The rate column is expressed in number of rows
per second.
SELECT stage_id, target, state, rate FROM assistant.report
WHERE target = 'public.film'::regclass;
stage_id | target | state | rate
----------+-------------+-----------+----------
1 | public.film | completed | 19162.59
2 | public.film | completed | 51389.37
Restart after interruption
The ability to restart a copy in batch mode in case of interruption is one of
the reasons why the primary key must be filled in the configuration. The
assistant relies on the last extracted primary key value (using a RETURNING
clause) to know the next restart point. In designing this feature, I had to
arbitrate the limitations imposed by this mechanism.
- Composite primary keys are not allowed, as the
RETURNINGclause can only return a single value; - Tables with composite primary keys cannot benefit from batch processing, and therefore cannot be restarted after interruption;
- Data is systematically sorted during extraction, even if batch processing is not enabled;
- The primary key column must be of numeric type.
The activation of a batch processing consists of updating the batchsize column
of the configuration table. Let’s take the example of the rental table:
UPDATE assistant.config SET batchsize = 1000
WHERE target = 'public.rental'::regclass;
SELECT invocation FROM assistant.plan('{public.rental}');
invocation
--------------------------
CALL assistant.copy(21);
(1 row)
The data transfer from the rental table is then divided into batches of 1000
rows. It is of course possible to combine this technique with parallelization,
the WHERE clause will do most of the work of repartition to prevent the same
line from being exported twice.
CALL assistant.copy(21);
TRUNCATE public.rental
SELECT count(rental_id) FROM mysql.rental WHERE rental_id > 0
INSERT INTO public.rental SELECT rental_id, ...
FROM mysql.rental WHERE rental_id > 0 ORDER BY rental_id LIMIT 1000
...
...
INSERT INTO public.rental SELECT rental_id, ...
FROM mysql.rental WHERE rental_id > 16005 ORDER BY rental_id LIMIT 1000
INSERT INTO public.rental SELECT rental_id, ...
FROM mysql.rental WHERE rental_id > 16049 ORDER BY rental_id LIMIT 1000
CALL
As soon as a query no longer returns any rows, the assistant considers that the
transfer is complete. The job table is updated at each iteration to follow the
last value of the primary key sequence.
SELECT target, lastseq FROM assistant.job
WHERE stage_id = 3 AND target = 'public.rental'::regclass;
target | lastseq
---------------+---------
public.rental | 16049
In case of interruption, it is possible to restart the transfer by calling the
copy() method with the same task identifier. The assistant takes care of
resuming the transfer from the last known primary key value.
CALL assistant.copy(21);
NOTICE: Executing: SELECT count(rental_id) FROM mysql.rental
WHERE rental_id > 16049
NOTICE: Executing: INSERT INTO public.rental SELECT rental_id, ...
FROM mysql.rental WHERE rental_id > 16049
ORDER BY rental_id LIMIT 1000
CALL
Conclusion
The design of such a tool was a small personal challenge in line with my research on migration to PostgreSQL with the exclusive help of Foreign Data Wrappers. My main source of inspiration remains the Ora2Pg project, one of the most advanced open-source tools to date in the field of migration.
I am aware of the technical limitations of this assistant, and the tinkering that remains to be done to make life easier for a consultant like me. In another article, I would like to present another tool called dispatch that I have been maintaining for some time and with which I answer questions about orchestration and traceability of migration steps.
By taking a step back, the basic concepts are there, any other tool in other languages could perfectly emerge and enrich the open-source ecosystem in the quest for migration to PostgreSQL.